AnyShare 7.0 海量文档的关键词搜索如何实现毫秒级响应?
索引原理简单介绍
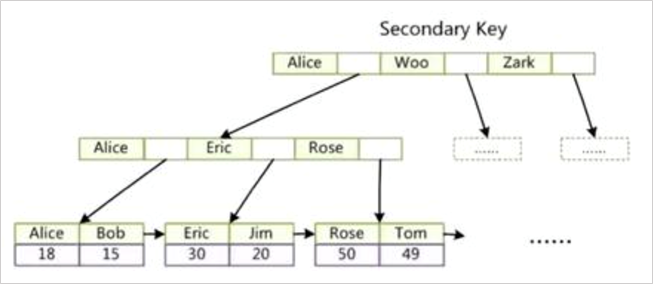
在关系数据库中,索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。

排序算法:搜索结果排序优先级的判决官
获得所有与搜索条件匹配的结果计算权重(Term weight)
检索词频率(TF,Term Frequency)
•检索词出现的频率,出现频率越高,相关性也越高
在关系数据库中,索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
传统海量数据搜索方式:数据库 SQL 查询
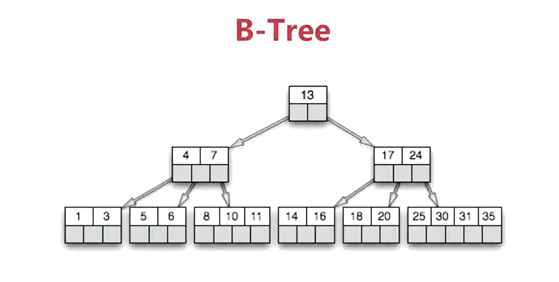
数据库的查询优化,可以根据字段建索引
查询某段时间内的数据,SQL查询获取数据,无索引:30s,有索引:2s
测试数据量:10407608(1000万)
SELECT * FROM `tf_hotspotdata_copy_test` WHERE collectTime BETWEEN '2014-12-06 00:00:00' AND '2014-12-10 21:31:55';
分词:决定文档中的内容能不能被搜索到
如何将一个句子拆分成不同的词组?
数据库的查询优化,可以根据字段建索引
查询某段时间内的数据,SQL查询获取数据,无索引:30s,有索引:2s
测试数据量:10407608(1000万)
SELECT * FROM `tf_hotspotdata_copy_test` WHERE collectTime BETWEEN '2014-12-06 00:00:00' AND '2014-12-10 21:31:55';
分词:决定文档中的内容能不能被搜索到
如何将一个句子拆分成不同的词组?
1.将文档分成一个一个单独的单词
2.去除标点符号
3.英文优化:全部小写,单词缩减为词根,单词转变为词根
4.中文使用 Jieba 分词算法(结巴分词)
排序算法:搜索结果排序优先级的判决官
获得所有与搜索条件匹配的结果计算权重(Term weight)
检索词频率(TF,Term Frequency)
•检索词出现的频率,出现频率越高,相关性也越高
•如:出现过 5 次要比只出现一次的相关性高
反向文档频率(IDF,Inverse Document Frequecy)
•每个检索词在索引中出现的频率?频率越高,相关性越低
•检索词出现在多数文档中会比出现在少数文档中的权重更低
字段长度准则
•字段的长度越长,相关性越低
•检索词出现在一个短的【标题】中,比同样的词出现在一个长的文本中权重更大
AnyShare 引入 elastic 实现海量文档数据的全文检索



•一个分布式的开源搜索和分析引擎,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据。
•同时还是一个近实时的搜索平台,这意味着从文档索引操作到文档变为可搜索状态之间的延时很短,一般只有一秒。
•分布式特性使得它可以扩展至数百台(甚至数千台)服务器,并处理 PB 量级的数据。
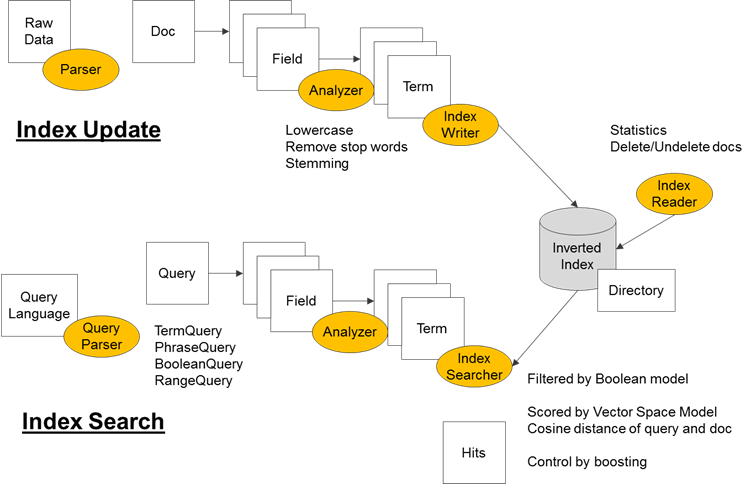
索引创建及索引搜索的基础流程
分布式集群:海量数据响应的基础支撑

内容分析及检索服务自身的关键特性

•一个分布式的开源搜索和分析引擎,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据。
•同时还是一个近实时的搜索平台,这意味着从文档索引操作到文档变为可搜索状态之间的延时很短,一般只有一秒。
•分布式特性使得它可以扩展至数百台(甚至数千台)服务器,并处理 PB 量级的数据。
索引创建及索引搜索的基础流程
分布式集群:海量数据响应的基础支撑
内容分析及检索服务自身的关键特性
赞
点个赞吧!
请就本文对您的益处进行评级:










