AnyRobot重要组件之Kafka——如何实现海量数据高性能存储
一、Kafka数据存储面临的问题
Kafka 是为了解决大数据的实时日志流而生的, 每天要处理的日志量级在千亿规模。对于日志流的特点主要包括 :- 数据实时产生。
- 海量数据存储与处理。
二、Kafka海量数据高性能存储秘密
Kafka实现海量数据高性能存储,主要通过以下5个特性来解决:- 顺序读写
- PageCache
- 零拷贝
- 消息批量处理
- 开启压缩
2.1、顺序读写提升磁盘 IO 性能
磁盘的特性是顺序读写性能要远远优于随机读写,在 SSD(固态硬盘)上,顺序读写的性能要比随机读写快几倍,如果是机械硬盘,这个差距会达到几十倍。操作系统每次从磁盘读写数据的时候,先要找到数据在磁盘上的物理位置,也就是寻址,然后再进行数据读写。如果是机械硬盘,这个寻址需要比较长的时间,它需要移动磁头,这是个机械运动,机械硬盘工作的时候会发出咔咔的声音,就是移动磁头发出的声音。
顺序读写相比随机读写省去了大部分的寻址时间,它只要寻址一次,就可以连续地读写下去,所以说,性能优于随机读写很多倍。
Kafka 充分利用了磁盘的这个特性。它的存储设计非常简单,对于每个分区,它把从 Producer 收到的消息,顺序地写入对应的 log 文件中,一个文件写满了,就开启一个新的文件这样顺序写下去,所以在写入磁盘时,可以使用顺序追加的方式来避免低效的磁盘寻址。在一个分区内,Kafka 采用 append 的方式进行顺序写入,这样即使是普通的机械磁盘,也可以有很高的性能。
这样一个简单的设计,充分利用了顺序读写这个特性,极大提升了 Kafka 在使用磁盘时的 IO 性能,从而实现海量数据的高效存储。
2.2、使用操作系统PageCache缓存消息,减少磁盘IO
Kafka 依赖文件系统来存储和缓存消息,以及典型的顺序追加写日志操作,它使用操作系统的 PageCache 来减少对磁盘 I/O 操作,即将磁盘的数据缓存到内存中,把对磁盘的访问转变为对内存的访问。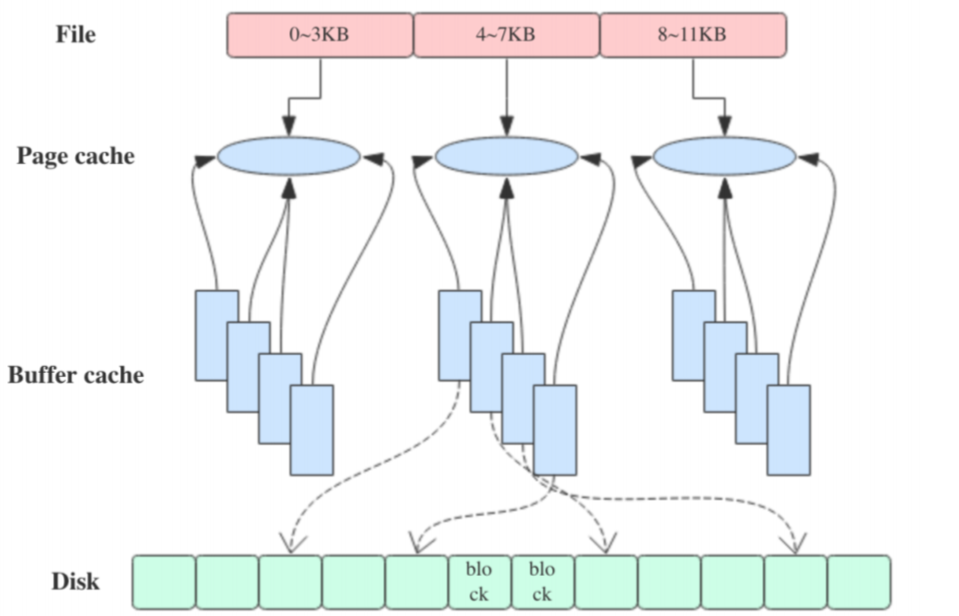
在 Kafka 中,大量使用了 PageCache, 这也是 Kafka 能实现高吞吐的重要因素之一, 当一个进程准备读取磁盘上的文件内容时,操作系统会先查看待读取的数据页是否在 PageCache 中,如果命中则直接返回数据,从而避免了对磁盘的 I/O 操作;如果没有命中,操作系统则会向磁盘发起读取请求并将读取的数据页存入 PageCache 中,之后再将数据返回给进程。同样,如果一个进程需要将数据写入磁盘,那么操作系统也会检查数据页是否在页缓存中,如果不存在,则 PageCache 中添加相应的数据页,最后将数据写入对应的数据页。被修改过后的数据页也就变成了脏页,操作系统会在合适的时间把脏页中的数据写入磁盘,以保持数据的一致性。
3、零拷贝(Zero-Copy)kafka主要通过两种零拷贝技术:mmap和sendfile,零拷贝不是指不需要拷贝,而是减少那些不必要的拷贝,从而减少额外的开销。
-
mmap(Memory Mapped Files)解决的是网络数据落盘。它将磁盘文件映射到内存中,之后通过修改内存来修改文件内容。需要注意的是,这个方式需要flush才会真正的将数据存入磁盘。kafka为此提供了一个参数(producer.type)来控制是否主动flush,有两个值——sync和async,sync是写入之后立即调用flush然后再返回,async是写入之后不调用flush直接返回。
-
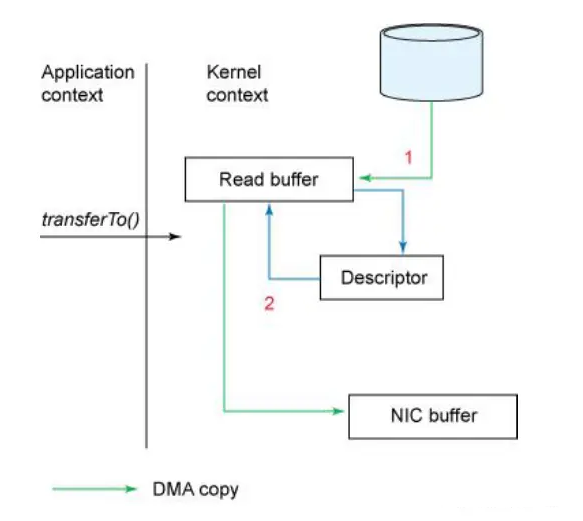
sendfile:解决的是磁盘到网络数据的传输。操作系统读取磁盘数据到内存缓存后,直接发送给网卡缓存,然后发送网络数据。
- 首先,从文件中找到消息数据,读到内存中;
- 然后,把消息通过网络发给客户端。
这个过程中,数据实际上做了 2 次或者 3 次复制:
- 从文件复制数据到 PageCache 中,如果命中 PageCache,这一步可以省掉;
- 从 PageCache 复制到应用程序的内存空间中,也就是我们可以操作的对象所在的内存;
- 从应用程序的内存空间复制到 Socket 的缓冲区,这个过程就是我们调用网络应用框架的 API 发送数据的过程。
4、消息批量处理
在Kafka内部,消息都是以“批”为单位处理的,Kafka的客户端SDK在实现消息发送逻辑的时候,采用了异步批量发送的机制。
当发送一条消息后,无论我们是同步发送还是异步发送,Kafka并不会立刻把这条消息发送出去,它会先把这条消息存放在内存中,然后选择合适的时机把缓存的所有消息组成一批,一次性的发给Broker。在Broker端,整个处理流程中,无论是写入磁盘、从磁盘读出来、还是复制到其他副本,批消息都不会被解开,一直是作为一条“批消息”进行处理的。在消费时,消息同样是以批为单位进行传递的,Consumer从Broker拉到一批消息后,在客户端把批消息解开,再一条一条交给用户代码处理。
这样,构建批消息和解开批消息分别在发送端和消费端的客户端完成,不仅减轻了Broker的压力,还减少了Broker处理请求的次数,提升了总体的处理能力。
5、开启压缩
在开启压缩时,Kafka 选择一批消息一起压缩,每一个批消息就是一个压缩分段。使用者也可以通过参数来控制每批消息的大小。
Kafka 在生产者上,对每批消息进行压缩,批消息在服务端不解压,消费者在收到消息之后再进行解压。简单地说,Kafka 的压缩和解压都是在客户端完成的,在服务端不用解压,就不会耗费服务端宝贵的 CPU 资源,同时还能获得压缩后,占用传输带宽小,占用存储空间小的这些好处。
请就本文对您的益处进行评级:










