AnyDATA Framework 2.0.0.0 版本发布通知
AnyDATA Framework 2.0.0.0 版本发布啦!本次发布新增了知识网络存储管理功能,并增加了对Nebula图数据库的支持,可以实现更高的图数据读写性能!此外全新的产品视觉设计,能够更加体现AnyDATA认知智能框架的特点。一起来看看新版本都做了哪些具体的更新吧:
【新增知识网络存储功能,提升图数据存储的拓展性】
历史版本的AnyDATA仅支持唯一内置的OrientDB图数据库作为知识的存储位置,并不具备拓展性。用户无法将自己存储在其他图数据库中图数据作为数据源接入到AnyDATA中,也不能选择其他的图数据库作为存储空间。当面对海量数据构建、高并发查询等需求时,很容易就会遇到性能瓶颈。因此在AnyDATA Framework 2.0.0.0版本中,新增加了知识网络存储管理的功能模块。该功能模块支持用户将第三方的图数据库接入到知识网络工作台中,作为图数据存储空间进行统一管理。
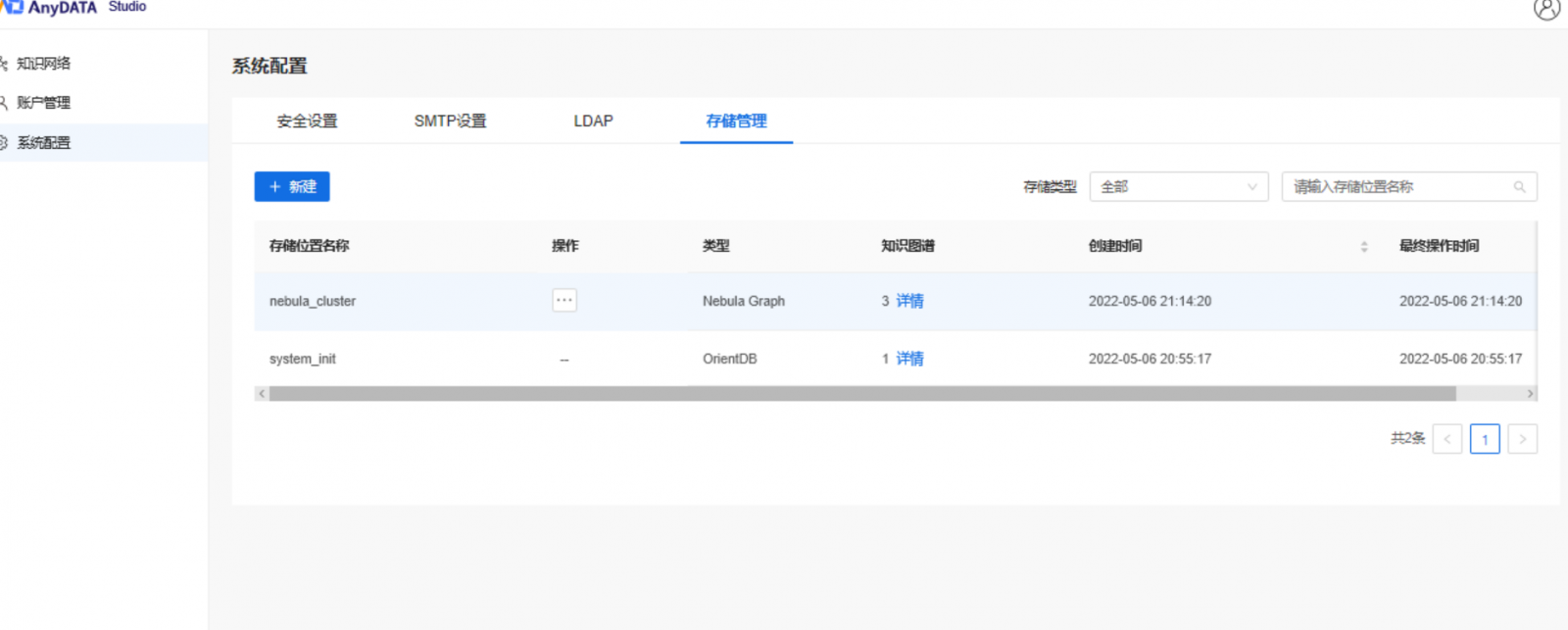
- AnyDATA的管理员账号可以创建外部的图数据库和全文索引存储。不同于 OrientDB,Nebula Graph 用于图数据全文检索需要使用外部索引进行存储(兼容 Pronton 提供的 OpenSearch)。。
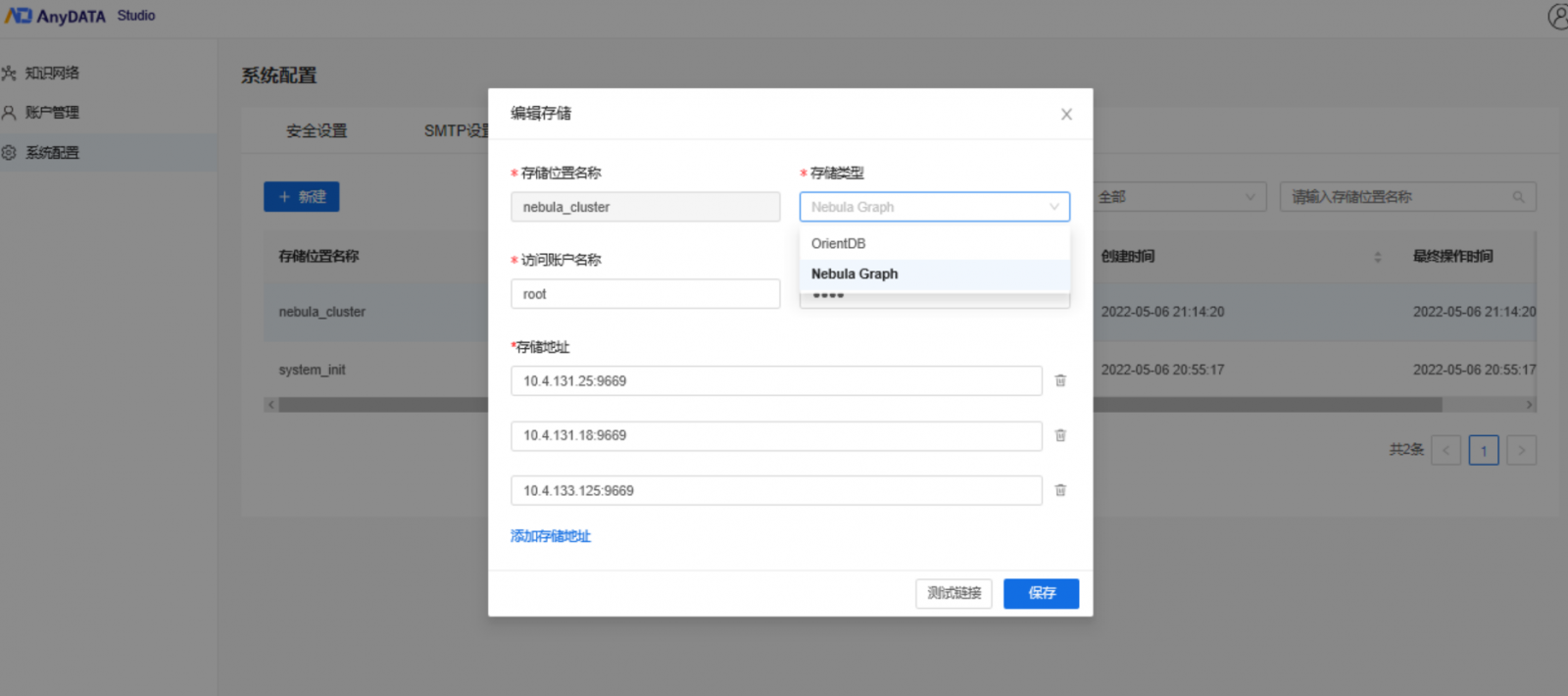
【兼容Nebula Graph图数据库,实现海量数据存储】
社区版的图数据库OrientDB对于分布式存储支持非常有限,导致写入大量数据时速度变慢。因此,AnyDATA Framework 2的最新版本增加了对Nebula Graph图数据库的支持。用户在构建领域知识网络时可以选择Nebula Graph图数据库作为存储空间,同时在知识图谱搜索场景中,支持使用Neubla进行图数据的搜索。
Nebula Graph 是一款开源的分布式图数据库(https://nebula-graph.io/),定位为大规模的属性图,以处理大规模海量数据为设计目标,是世界上唯一能够容纳千亿个顶点和万亿条边,并提供毫秒级查询延时的图数据库解决方案。在性能上,可以实现毫秒级快速响应,非常适用于海量高并发的应用场景。此外,Nebula 为国产的开源图数据库厂商,可以满足部分客户的国产化要求。
【全新的知识网络管理与认知引擎页面,显著提升视觉效果】
为了更能体现框架的特点,AnyDATA知识网络工作台对主要页面的视觉效果和交互逻辑做了较大更新。新的产品页面设计突出了产品的架构层级,可以让用户更加清晰地区分知识网络与知识图谱、知识网络与认知引擎、以及认知引擎与高级搜索这些概念之间的关系,大幅提升了用户的使用体验。
AnyDATA Framework 2 明确了“领域知识网络”的概念,领域知识网络是某个领域内的知识表示集合,包括知识图谱、语言模型、决策树、规则知识库等在内的知识表示集合。目前 AnyDATA 工作台中已支持知识图谱这种知识表示方式,用户可以在一个领域知识网络内创建多个知识图谱,并基于知识网络进行知识管理与后续应用的开发。
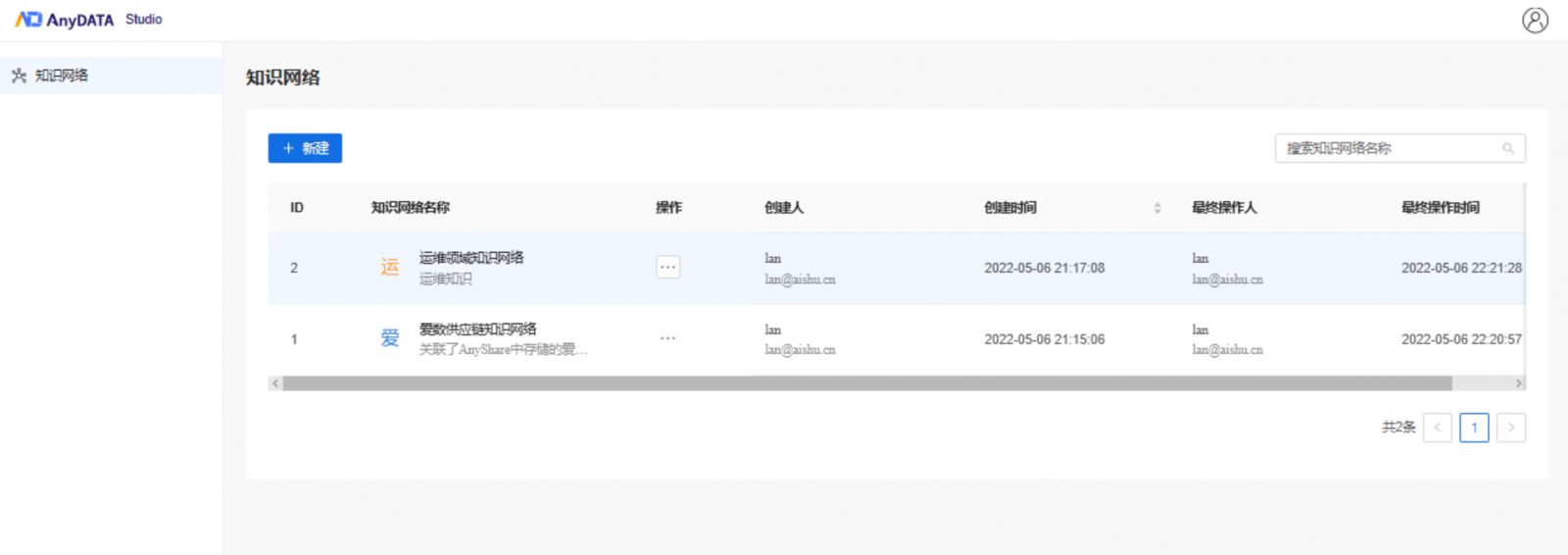
点击进入知识图谱页面,每个图谱分为四个板块进行展示,分别为「关于」、「分析」、「本体」、「任务」。用户可以在这些板块中获取知识图谱信息、查看图谱的本体模型、进行图谱分析、或管理图谱任务。

在知识网络管理中新增了认知引擎板块,并在板块下支持认知搜索(即历史版本中的高级搜索功能)和策略配置(即历史版本中的高级搜索策略配置)。进入知识网络后新增,用户点击「认知引擎」,即可进入认知引擎板块。

【AnyDATA Framework2助力KnowledgeCenter知识主题功能优化】
旧旧版本的主题发现直接采用内容知识模型中的 Label 作为主题发现的结果,存在如下问题导致KnowledgeCenter用户体验不好:
【新增知识网络存储功能,提升图数据存储的拓展性】
历史版本的AnyDATA仅支持唯一内置的OrientDB图数据库作为知识的存储位置,并不具备拓展性。用户无法将自己存储在其他图数据库中图数据作为数据源接入到AnyDATA中,也不能选择其他的图数据库作为存储空间。当面对海量数据构建、高并发查询等需求时,很容易就会遇到性能瓶颈。因此在AnyDATA Framework 2.0.0.0版本中,新增加了知识网络存储管理的功能模块。该功能模块支持用户将第三方的图数据库接入到知识网络工作台中,作为图数据存储空间进行统一管理。
- AnyDATA的管理员账号可以创建外部的图数据库和全文索引存储。不同于 OrientDB,Nebula Graph 用于图数据全文检索需要使用外部索引进行存储(兼容 Pronton 提供的 OpenSearch)。。
【兼容Nebula Graph图数据库,实现海量数据存储】
社区版的图数据库OrientDB对于分布式存储支持非常有限,导致写入大量数据时速度变慢。因此,AnyDATA Framework 2的最新版本增加了对Nebula Graph图数据库的支持。用户在构建领域知识网络时可以选择Nebula Graph图数据库作为存储空间,同时在知识图谱搜索场景中,支持使用Neubla进行图数据的搜索。
Nebula Graph 是一款开源的分布式图数据库(https://nebula-graph.io/),定位为大规模的属性图,以处理大规模海量数据为设计目标,是世界上唯一能够容纳千亿个顶点和万亿条边,并提供毫秒级查询延时的图数据库解决方案。在性能上,可以实现毫秒级快速响应,非常适用于海量高并发的应用场景。此外,Nebula 为国产的开源图数据库厂商,可以满足部分客户的国产化要求。
【全新的知识网络管理与认知引擎页面,显著提升视觉效果】
为了更能体现框架的特点,AnyDATA知识网络工作台对主要页面的视觉效果和交互逻辑做了较大更新。新的产品页面设计突出了产品的架构层级,可以让用户更加清晰地区分知识网络与知识图谱、知识网络与认知引擎、以及认知引擎与高级搜索这些概念之间的关系,大幅提升了用户的使用体验。
AnyDATA Framework 2 明确了“领域知识网络”的概念,领域知识网络是某个领域内的知识表示集合,包括知识图谱、语言模型、决策树、规则知识库等在内的知识表示集合。目前 AnyDATA 工作台中已支持知识图谱这种知识表示方式,用户可以在一个领域知识网络内创建多个知识图谱,并基于知识网络进行知识管理与后续应用的开发。
点击进入知识图谱页面,每个图谱分为四个板块进行展示,分别为「关于」、「分析」、「本体」、「任务」。用户可以在这些板块中获取知识图谱信息、查看图谱的本体模型、进行图谱分析、或管理图谱任务。
在知识网络管理中新增了认知引擎板块,并在板块下支持认知搜索(即历史版本中的高级搜索功能)和策略配置(即历史版本中的高级搜索策略配置)。进入知识网络后新增,用户点击「认知引擎」,即可进入认知引擎板块。
【AnyDATA Framework2助力KnowledgeCenter知识主题功能优化】
旧旧版本的主题发现直接采用内容知识模型中的 Label 作为主题发现的结果,存在如下问题导致KnowledgeCenter用户体验不好:
(1)label生成的准确性不够导致产生很多无效主题;
(2)没有相关的筛选和排序,无法选择高效主题;
(3)主题数量过多且冗杂
(4)对于非领域新词类的主题没有覆盖
基于 KnowledgeCenter 的规划,知识主题采用手工配置的方式,因此 AnyDATA 仅负责标签生成,并通过标签将用户手工输入的主题与文档进行关联,所以 Label 不在直接用作主题,而是回归其字面的本意“标签”。
本次版本在标签生成的算法层面算法层面,除了保留原有的新词发现算法之外,还新增非新词的关键词发现,并对两部分结果进行排序,排除无关标签;同时增加对标签描述的提取,描述可作为标签的解释,也可以使标签提取结果更加精准,提升了KnowledgeCenter创建主题时的用户使用体验与工作效率。
赞
点个赞吧!
请就本文对您的益处进行评级:










