AnyDATA Framework 3.0.0.2版本发布
本次发布AnyDATA Framework 3.0.0.2版本,发布内容如下:
此外,通过在AnyDATA上统一进行管理,可以更加方便开发者比较、调取不同的大模型,并对定期及时地进行更新和维护,从而助力后续知识网络的构建和认知应用的开发。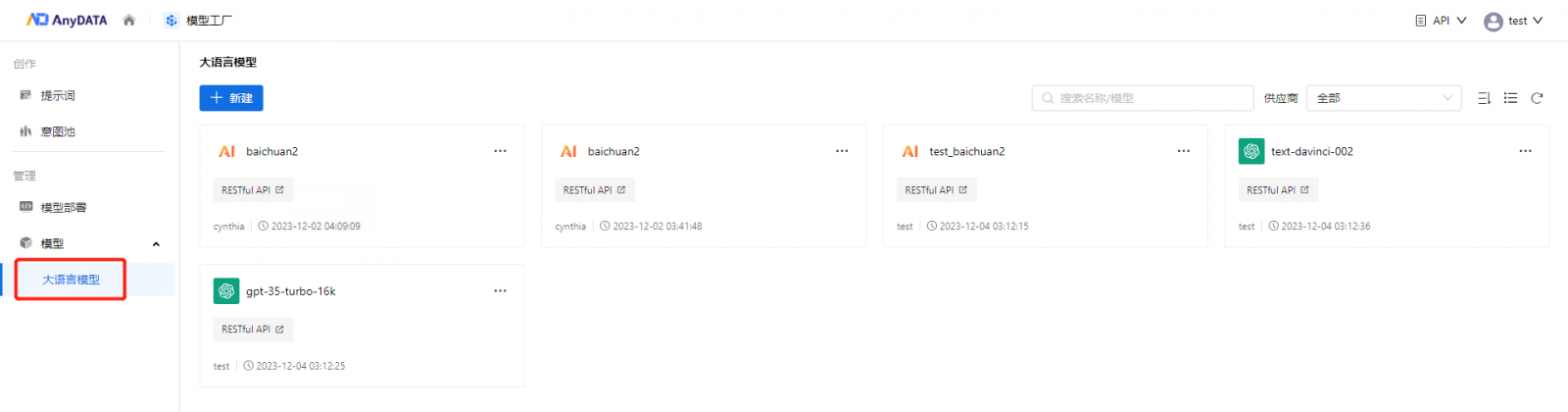
图1 大模型接入

因此AnyDATA新增提示词工程模块,支持用户进行文本生成型或对话型提示词的开发,并通过配置变量、调整模型参数,在线优化调试提示词的质量,以达到期望的效果。此外,通过对提示词统一进行管理和维护,也方便了不同用户之间的协作开发和使用。
例如,当某用户想要给自己文档中的内容总结一个标题时,他就可以选择一个大模型进行总结标题提示词的开发。比如将提示词可写成:请给该段文字总结一个标题,字数不超过{{number}}个字。用户后续调用该提示词时,仅需输入标题字数,即可获得大模型为其总结的结果标题。

此外,AnyDATA还总结了不同场景下的提示词模板,例如阅读理解场景下的提示词,可以让大模型理解某篇材料,并基于材料内容去回答用户的问题。丰富的提示词模板能够辅助用户进行提示词的开发,降低用户对大模型的使用门槛,提升使用效率。

例如在生产计划场景中,工作人员需计算出如何用最少的原材料,生产出最多的产品,并且保证产品的存储量在一个合理的范围以便下一次的供应,然而通过手动计算解决这些问题往往非常复杂,涉及到多个目标、资源以及各种限制条件,决策效率太低。因此利用运筹优化模型则可以帮助用户系统地分析,快速地提供最优的决策方案,从而最大化利益,最小化成本。


例如当用户想要查询“某区的医院有哪些医生”,则基于“医生”在实体链接词库中的存储位置,可以找到“医生”这个实体类所在的图谱,从而进入图谱中去找到答案返回给用户。

例如当用户想要查询“某区的医院有哪些医师”时,则根据近义词词库,得知“医师”的同义词为“医生”,因此找到“医生”这个实体类所在的图谱,便可进入图谱中找到答案返回给用户。
例如同样一句话,默认分词器可能只能识别为“化妆/和服/装”,而根据词库中的分词结果则是“化妆/和/服装”,显然后者的分词效果更加。
例如,构建一个电影知识图谱,其中存在一个[电影]实体,包含[剧情简介]的属性。假设某用户看到了一段感兴趣的剧情介绍,想要根据这段内容搜索其所属的电影。这时如果只是基于全文检索,通过关键词匹配是很难找到结果的;但是基于向量检索技术,通过向量相似度匹配,就可进行语义层面的匹配,找到这部电影,并得到有类似剧情的电影。

而通过AnyDATA提供的标准推荐算法服务,则可以为数据分析师自动推荐标准的名称作为参考。比如当用户录入字段“年月日”时,根据模型算法推断,会将标准的字段名“日期”推荐给用户。当一次返回5个或以上的结果时,推荐的准确率可以达到90%以上,从而助力数据分析师对数据标准一致性的维护。
例如当用户询问“研发构建信息”字段信息后,即可返回该字段及其同义词所属的表信息。
此外,对于用户的问句,可基于同义词库找到分词中可能存在的同义词,并利用停用词库过滤掉无意义的词,最终实现对问句语义的精准理解,并进入图谱找到答案。

【认知工作台-模型工厂】
一、大模型接入
新版本支持用户在AnyDATA中接入大模型进行使用。用户只需选择大模型供应商,填写API配置信息,便可将大模型添加进来。然后通过调用接口,填写相应的模型参数,便可使用大模型。此外,通过在AnyDATA上统一进行管理,可以更加方便开发者比较、调取不同的大模型,并对定期及时地进行更新和维护,从而助力后续知识网络的构建和认知应用的开发。
图1 大模型接入
图2 大模型接入配置
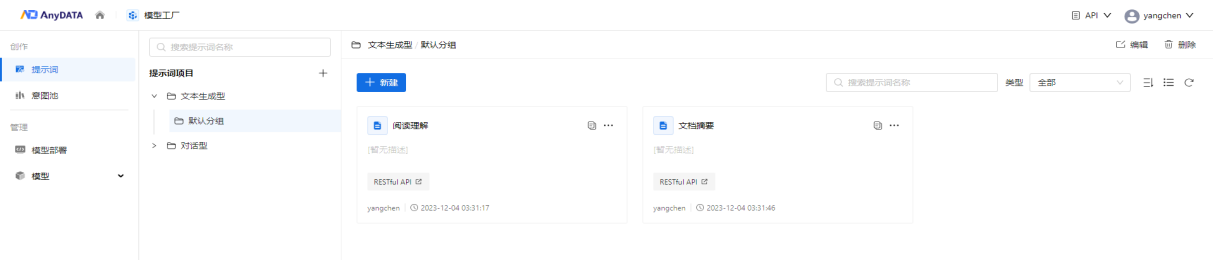
二、提示词工程引入
提示词可以帮助大型语言模型更好地理解上下文,理解用户的需求,指导其生成更加准确和连贯的文本。但当用户不理解大模型的内部机制和工作原理,或是不了解一些专业领域时,就难以写出高质量的提示词,大模型也难以给出期望的结果。因此AnyDATA新增提示词工程模块,支持用户进行文本生成型或对话型提示词的开发,并通过配置变量、调整模型参数,在线优化调试提示词的质量,以达到期望的效果。此外,通过对提示词统一进行管理和维护,也方便了不同用户之间的协作开发和使用。
例如,当某用户想要给自己文档中的内容总结一个标题时,他就可以选择一个大模型进行总结标题提示词的开发。比如将提示词可写成:请给该段文字总结一个标题,字数不超过{{number}}个字。用户后续调用该提示词时,仅需输入标题字数,即可获得大模型为其总结的结果标题。
图3 提示词管理
图4 提示词开发与调试
此外,AnyDATA还总结了不同场景下的提示词模板,例如阅读理解场景下的提示词,可以让大模型理解某篇材料,并基于材料内容去回答用户的问题。丰富的提示词模板能够辅助用户进行提示词的开发,降低用户对大模型的使用门槛,提升使用效率。
图5 提示词模板
三、新增内置模型
新增运筹优化模型,帮助用户解决在生产、排班、制造等多个领域复杂的决策问题。例如在生产计划场景中,工作人员需计算出如何用最少的原材料,生产出最多的产品,并且保证产品的存储量在一个合理的范围以便下一次的供应,然而通过手动计算解决这些问题往往非常复杂,涉及到多个目标、资源以及各种限制条件,决策效率太低。因此利用运筹优化模型则可以帮助用户系统地分析,快速地提供最优的决策方案,从而最大化利益,最小化成本。
图6 新增运筹优化模型
【认知工作台-知识网络】
【认知工作台-知识网络】
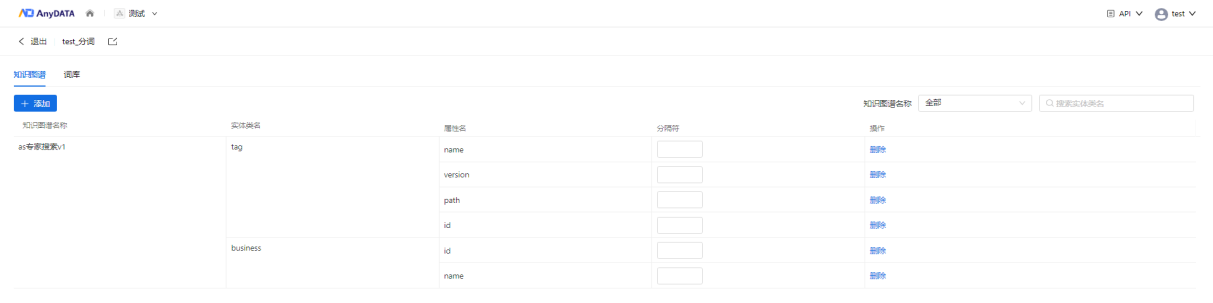
一、知识网络生成之概念库
- 基于知识图谱生成词库
图7 新建词库
首先,实体链接词库将知识图谱中的实体及其属性以词条的形式进行结构化的存储,在后续文本分析或搜索问答等过程中,可以将文本中的实体与知识图谱中的实体进行关联,从而更精确的从图谱中找到答案。例如当用户想要查询“某区的医院有哪些医生”,则基于“医生”在实体链接词库中的存储位置,可以找到“医生”这个实体类所在的图谱,从而进入图谱中去找到答案返回给用户。
图8 实体链接词库
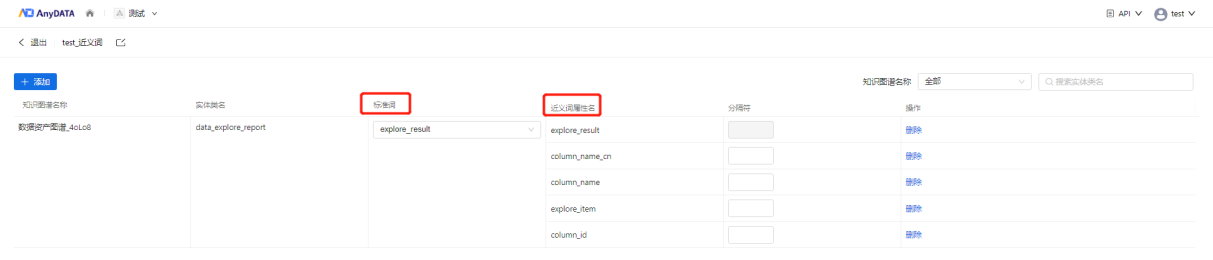
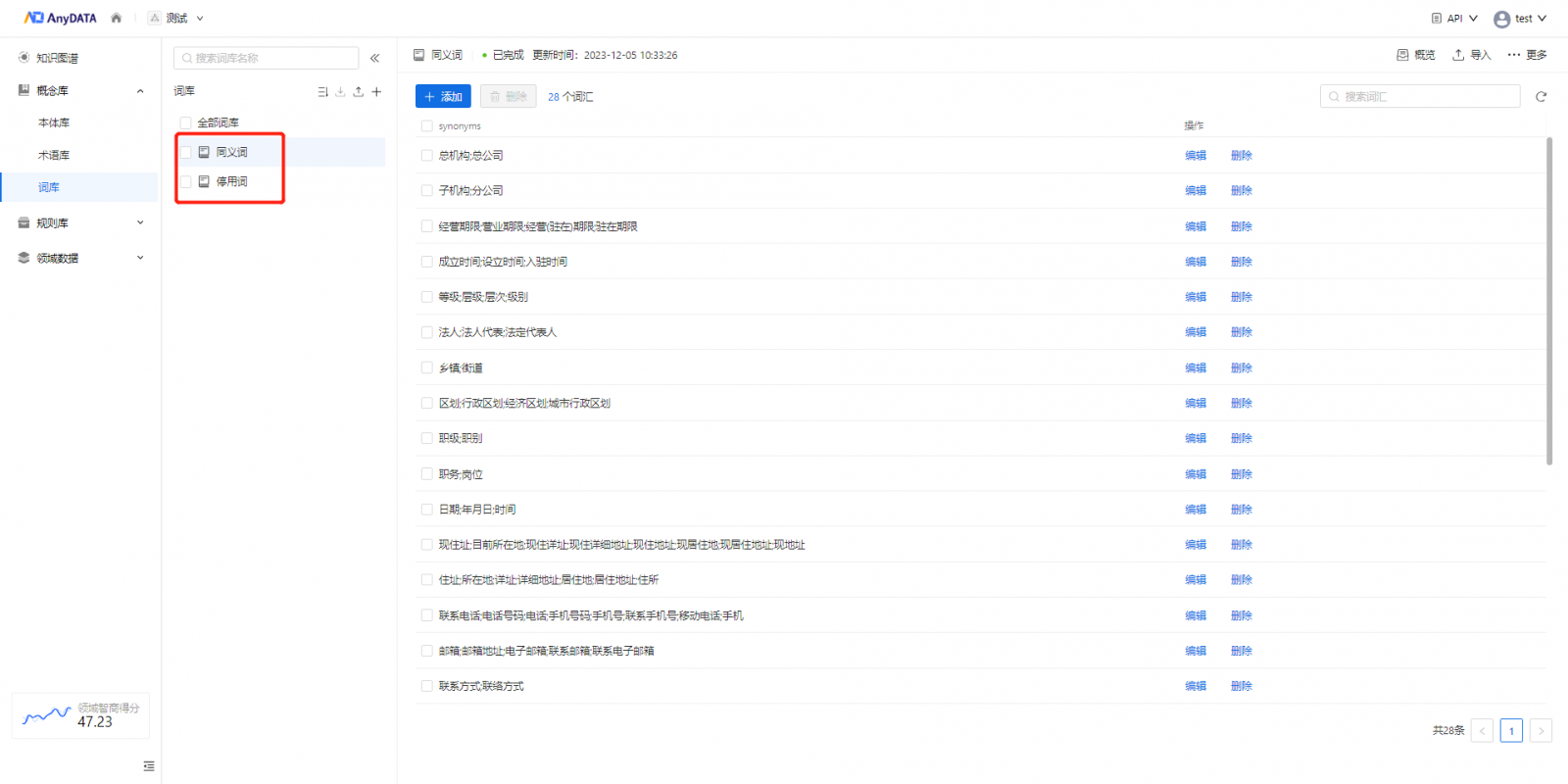
近义词词库可以支持用户基于知识图谱中实体标准词属性,添加其近义词,后续在搜索问答等场景中,可用来完成词义消歧、语义相似性计算等文本增强任务,助力NLP语义理解用户意图,从而返回期望的结果。例如当用户想要查询“某区的医院有哪些医师”时,则根据近义词词库,得知“医师”的同义词为“医生”,因此找到“医生”这个实体类所在的图谱,便可进入图谱中找到答案返回给用户。
图9 近义词词库
分词词库则支持用户自定义分词器的语料,在后续文本分析或搜索问答场景中,相比默认的分词器,利用分词词库中的内容可以更准确的对文本、问句进行理解。例如同样一句话,默认分词器可能只能识别为“化妆/和服/装”,而根据词库中的分词结果则是“化妆/和/服装”,显然后者的分词效果更加。
图10 分词词库
二、知识网络生成之知识图谱
- 知识图谱构建新增配置向量索引
例如,构建一个电影知识图谱,其中存在一个[电影]实体,包含[剧情简介]的属性。假设某用户看到了一段感兴趣的剧情介绍,想要根据这段内容搜索其所属的电影。这时如果只是基于全文检索,通过关键词匹配是很难找到结果的;但是基于向量检索技术,通过向量相似度匹配,就可进行语义层面的匹配,找到这部电影,并得到有类似剧情的电影。
图11 向量索引配置
- 支持使用RESTful API批量删除关系类
【认知工作台-认知应用】
一、认知搜索应用
- 面向AnyFabric的标准推荐算法效果优化
而通过AnyDATA提供的标准推荐算法服务,则可以为数据分析师自动推荐标准的名称作为参考。比如当用户录入字段“年月日”时,根据模型算法推断,会将标准的字段名“日期”推荐给用户。当一次返回5个或以上的结果时,推荐的准确率可以达到90%以上,从而助力数据分析师对数据标准一致性的维护。
图12 标准推荐
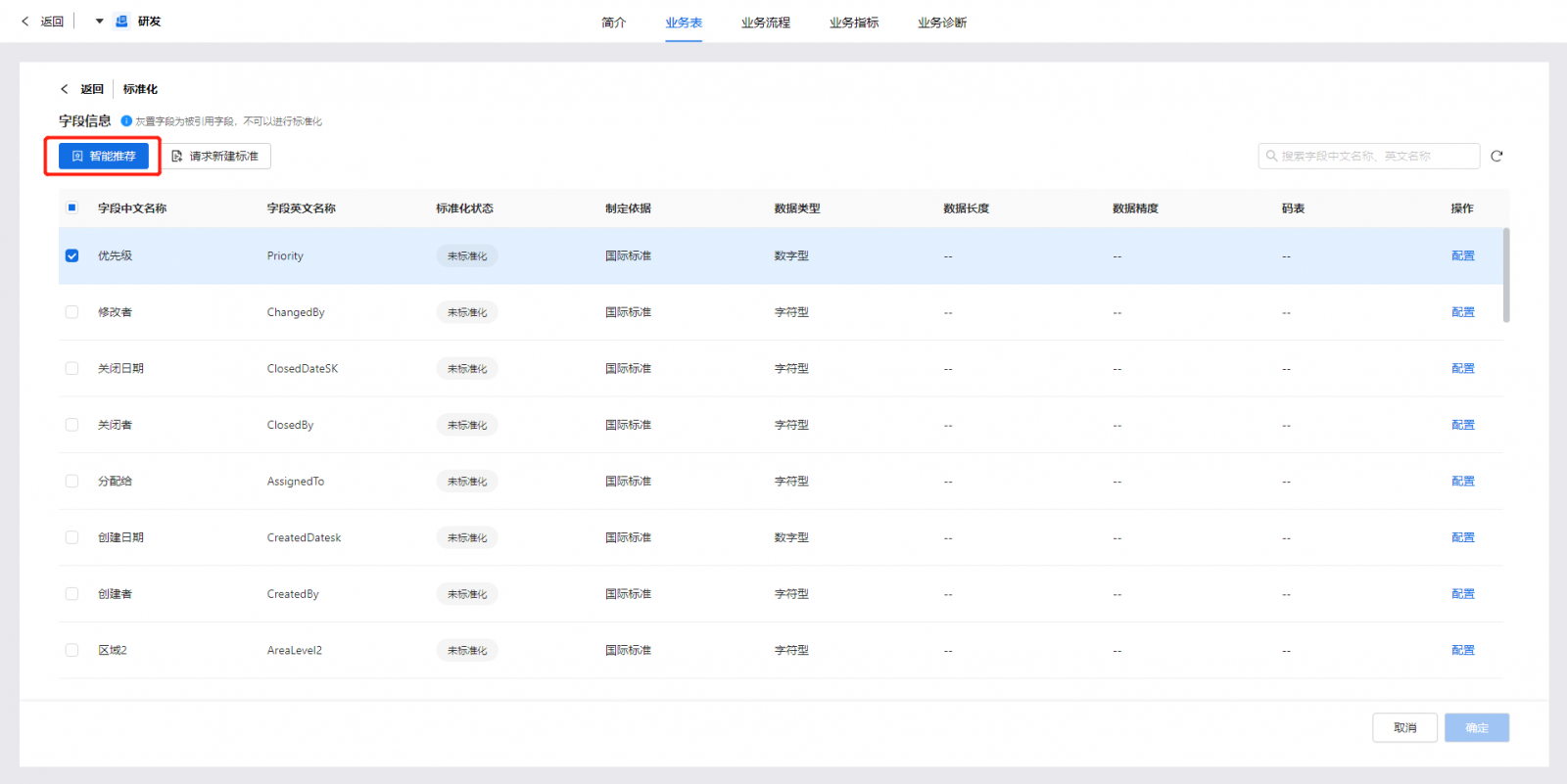
新版本还支持用户基于数据资产图谱找到期望的数据资源目录,并能根据用户问句中的相关同义词去找寻数据。例如当用户询问“研发构建信息”字段信息后,即可返回该字段及其同义词所属的表信息。
图13 数据资源目录查询
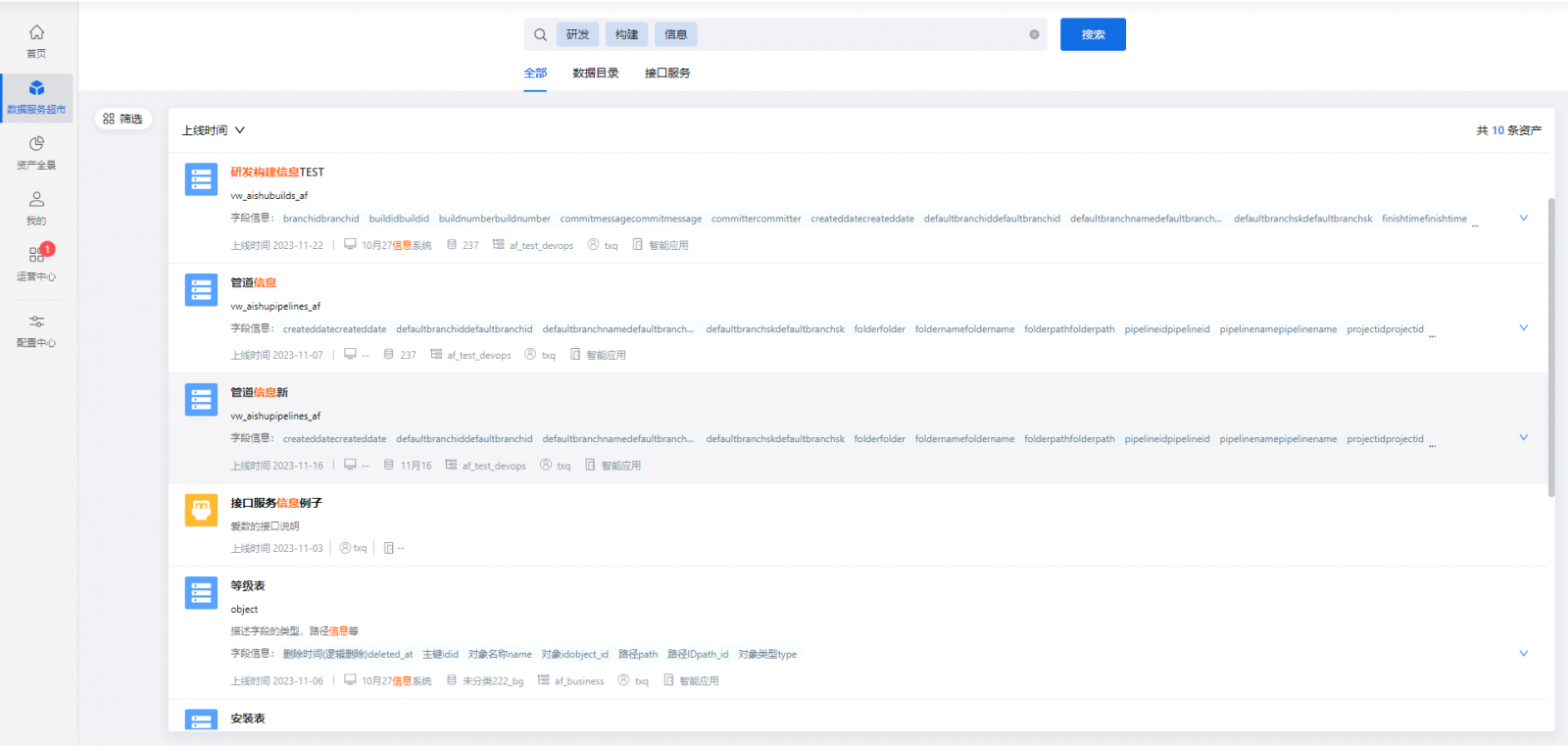
此外,对于用户的问句,可基于同义词库找到分词中可能存在的同义词,并利用停用词库过滤掉无意义的词,最终实现对问句语义的精准理解,并进入图谱找到答案。
图14 同义词、停用词词库
二、支持通过应用名称访问认知应用
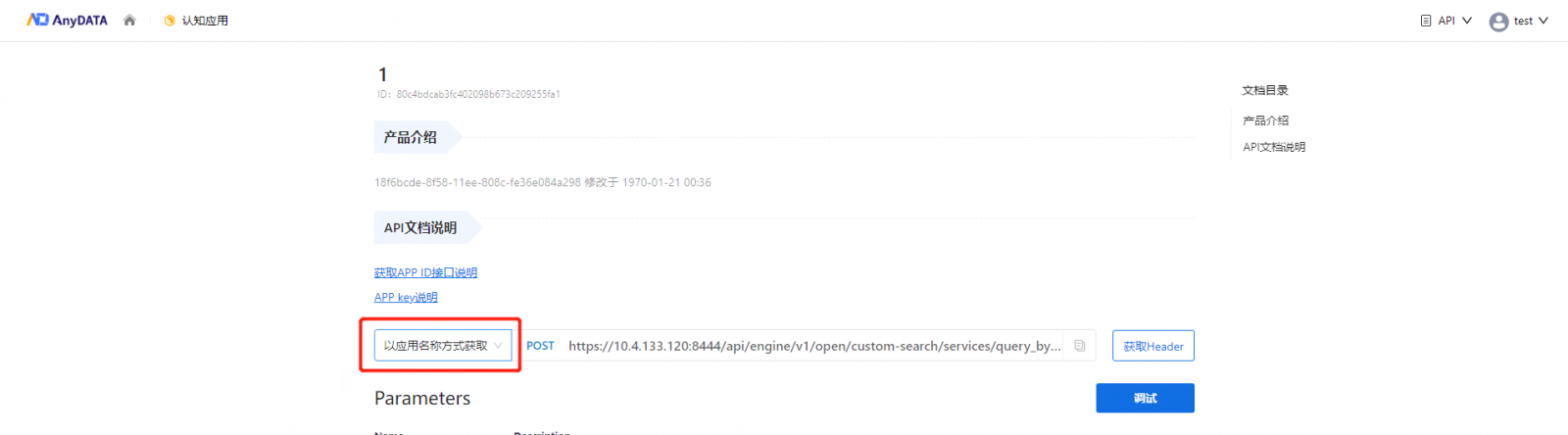
新版本增加了基于应用名称访问认知应用的方式,为开发者提供更多应用集成的选择。当开发者需要在上层应用中集成AnyDATA的认知应用时,可以直接通过唯一的应用名称进行调用,无需再修改API配置中认知应用的id。
图15 通过应用名称进行访问
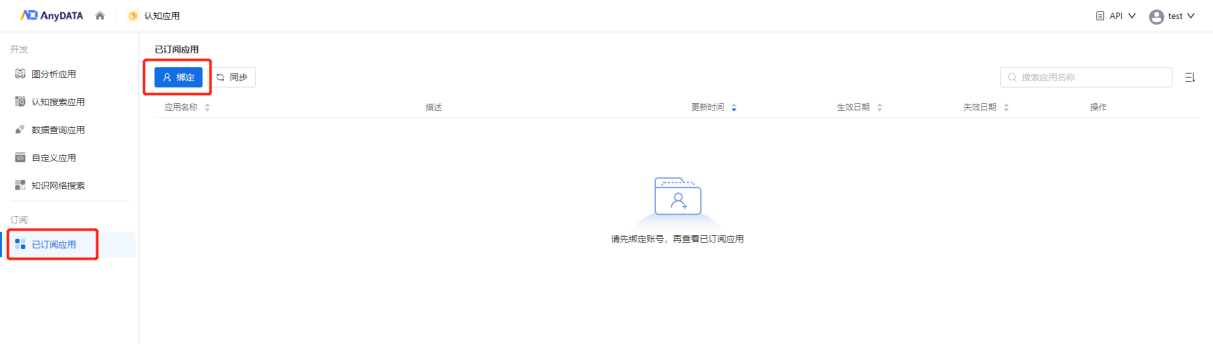
三、接入已订阅认知应用流程优化
当前版本下,若某用户想要在AnyDATA上使用自己在数据交易系统中订阅的认知应用时,需先行绑定数据交易系统的地址、端口等信息进行授权。而新版本中用户可直接从“认知应用-已订阅应用”模块登陆数据交易系统进行账号绑定,便可将该账号订阅的领域认知应用导入进来使用。
图16 账号绑定入口
图17 数据交易系统账号绑定
【其他优化】
【其他优化】
- 参考公司RESTful API设计规范,对API、API文档和数据库进行了优化,统一接口定义的字段语义和格式,并对接口进行统一高效的版本管理,方便后续部门之间的协作。
- 遵照公司统一的UI规范,对产品界面中的按钮和列表进行了调整,提供更加标准良好的交互体验。
- AnyDATA主模块支持使用公司全新版本的Proton,实现更简便安全的产品部署。
赞
点个赞吧!
请就本文对您的益处进行评级:










