AnyRobot如何实现海量数据的快速检索
AnyRobot对于用户的最大价值有哪些,首当其冲的肯定包括快速检索用户所需的有效日志信息。
随着用户系统越来越复杂,需要收集的日志量也呈指数型增长,经常存储的日志量达到TB级别。那么AnyRobot是如何实现在海量数
据中进行快速检索,显然离不开搜索引擎的帮助,AnyRobot底层使用的搜索引擎就是ElasticSearch。
ElasticSearch是基于 Lucene 引擎构建的开源分布式搜索分析引擎,可以提供针对 PB 数据的近实时查询,广泛用在全文检索、日志
分析、监控分析等场景。
在介绍ElasticSearch搜索原理之前,我们首先研究一个问题,ElasticSearch对比传统关系型数据库(如Mysql),它的优势有哪些,为
什么不能使用Mysql?
索引来提升搜索速率,避免全文检索,但是存在以下2个主要问题:
首先什么是倒排索引,简单来说通过文档来查找关键词等数据的我们称为正排索引,返之,通过关键词来查找文档的形式我们称之为
倒排索引。例如我们目前有以下三个文档
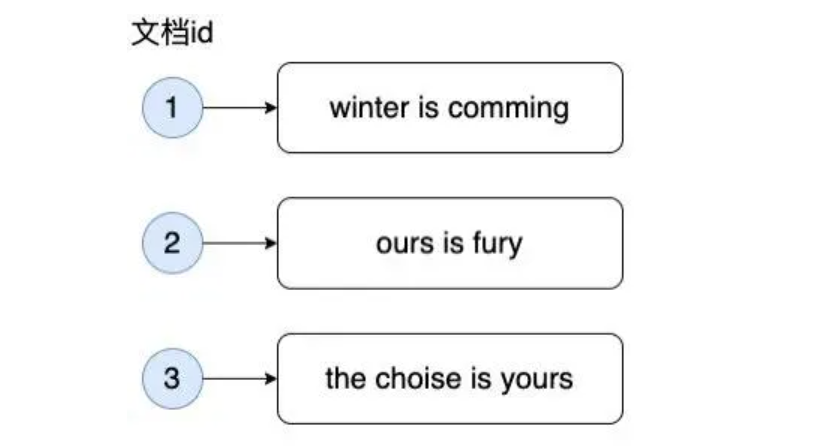
如果要搜索fury字段,正排索引需要查找所有文档进行检索,但是使用倒排索引首先会将每个文档内容进行分词,小写化等,然后建
立每个分词与包含有此分词的文档之前的映射关系,得到类似如下映射关系
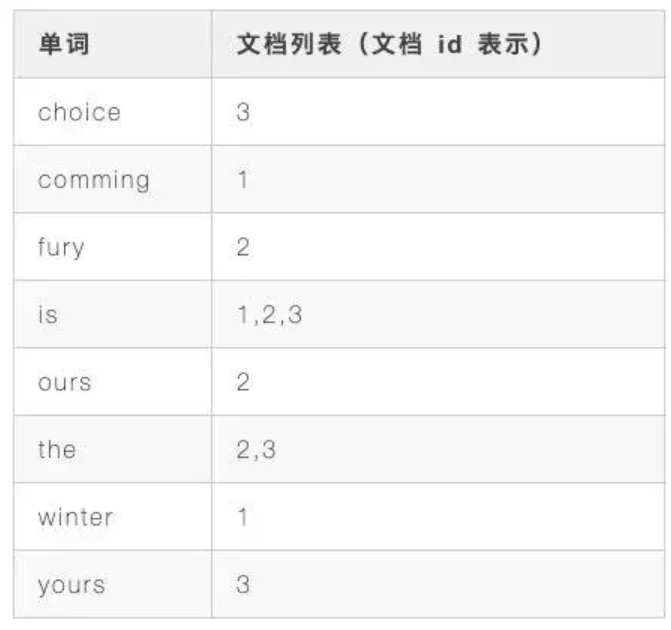
此时只需要进行一次检索即可,当然上述只是为了简要解释倒排索引原理。
度的拆分,会穷尽各种可能的组合。
随着用户系统越来越复杂,需要收集的日志量也呈指数型增长,经常存储的日志量达到TB级别。那么AnyRobot是如何实现在海量数
据中进行快速检索,显然离不开搜索引擎的帮助,AnyRobot底层使用的搜索引擎就是ElasticSearch。
ElasticSearch是基于 Lucene 引擎构建的开源分布式搜索分析引擎,可以提供针对 PB 数据的近实时查询,广泛用在全文检索、日志
分析、监控分析等场景。
在介绍ElasticSearch搜索原理之前,我们首先研究一个问题,ElasticSearch对比传统关系型数据库(如Mysql),它的优势有哪些,为
什么不能使用Mysql?
Mysql数据库在大数据搜索的局限性:
MySQL 架构天生不适合海量数据查询,它只适合海量数据存储,但无法应对海量数据下各种复杂条件的查询。可能有人会想到添加索引来提升搜索速率,避免全文检索,但是存在以下2个主要问题:
- 添加索引会极大增加存储成本,不可能为所有搜索场景都添加单独索引。
- 存在无法添加索引的场景,不可避免的触发全表扫描。
ElasticSearch的优势:
术业有专攻,海量数据查询还得用专门的搜索引擎,这其中ElasticSearch是当之无愧的王者。它主要有以下三个特点:
- 轻松支持各种复杂的查询条件:利用高效的倒排索引,实现任意复杂查询条件下的全文检索需求。
- 可扩展性强:天然支持分布式存储,支持横向扩容,轻松处理 PB 级别的结构化或非结构化数据。
- 高可用,容灾性能好:通过使用主备节点,以及故障的自动探测与恢复,有力地保障了高可用。
倒排索引介绍:
针对高效检索的实现,我们来重点剖析倒排索引——ElasticSearch的核心功能点。首先什么是倒排索引,简单来说通过文档来查找关键词等数据的我们称为正排索引,返之,通过关键词来查找文档的形式我们称之为
倒排索引。例如我们目前有以下三个文档
如果要搜索fury字段,正排索引需要查找所有文档进行检索,但是使用倒排索引首先会将每个文档内容进行分词,小写化等,然后建
立每个分词与包含有此分词的文档之前的映射关系,得到类似如下映射关系
此时只需要进行一次检索即可,当然上述只是为了简要解释倒排索引原理。
AnyRobot中日志检索实现:
首先AnyRobot采用IK分词器,将一整段日志信息切分成单独词条,支持中文日志,同时采用ik_max_word模式,会将文本做最细粒度的拆分,会穷尽各种可能的组合。
GET _analyze
{
"analyzer": "ik_max_word",
"text": ["中文分词语"]
}
结果
{
"tokens" : [
{
"token" : "中文",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "分词",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "词语",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
}
]
}
在对原始日志进行分词拆分成相应的team后,如何从海量的term中查询所需数据,遍历一遍显然也是不现实的,于是乎就有了term
dictionary。ElasticSearch为了能快速查找到 term,将所有的 term 排了一个序,用 B+树建立索引词典指向被索引的数据。但是如
果把整个 term dictionary 放在内存,内存资源肯定不足以存储,因此又引申出term index的概念。使用 "term index -> term
dictionary -> postings list" 的倒排索引结构,通过 FST 压缩放入内存,进一步提高搜索效率。
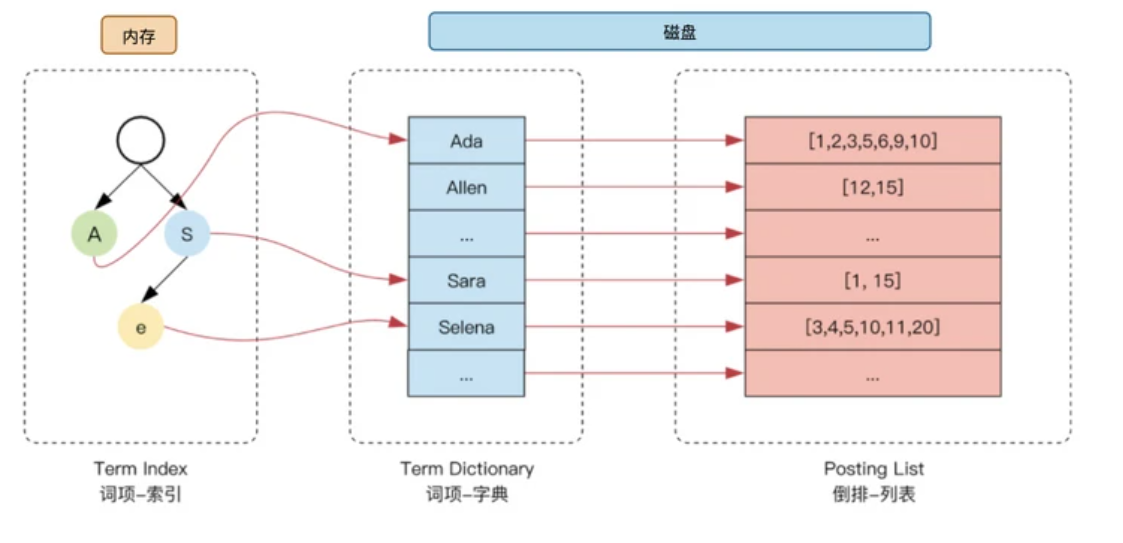 当然以上只是AnyRobot底层使用的ElasticSearch中倒排索引的基本理论,在实际产品中,还需要进一步考虑如何压缩数据,如何实
现快速联合查询等一系列问题。产品中通过Frame of Reference技术,压缩posting list 的空间消耗。使用 Roaring Bitmap 技术
来缓存搜索结果,保证高频 filter 查询速度的同时降低存储空间消耗。
在联合查询时,在有 filter cache 的情况下,会直接利用位图的原生特性快速求交并集得到联合查询结果,否则使用 skip list 对多个
postings list 求交并集,跳过遍历成本并且节省部分数据的解压缩 cpu 成本。
由于篇幅限制,本文就不对以上技术做具体原理讲解。
同时由于AnyRobot云原生架构,原生支持分布式,可以通过水平扩容,提升数据读写并发能力,提供更高的搜索性能
当然以上只是AnyRobot底层使用的ElasticSearch中倒排索引的基本理论,在实际产品中,还需要进一步考虑如何压缩数据,如何实
现快速联合查询等一系列问题。产品中通过Frame of Reference技术,压缩posting list 的空间消耗。使用 Roaring Bitmap 技术
来缓存搜索结果,保证高频 filter 查询速度的同时降低存储空间消耗。
在联合查询时,在有 filter cache 的情况下,会直接利用位图的原生特性快速求交并集得到联合查询结果,否则使用 skip list 对多个
postings list 求交并集,跳过遍历成本并且节省部分数据的解压缩 cpu 成本。
由于篇幅限制,本文就不对以上技术做具体原理讲解。
同时由于AnyRobot云原生架构,原生支持分布式,可以通过水平扩容,提升数据读写并发能力,提供更高的搜索性能
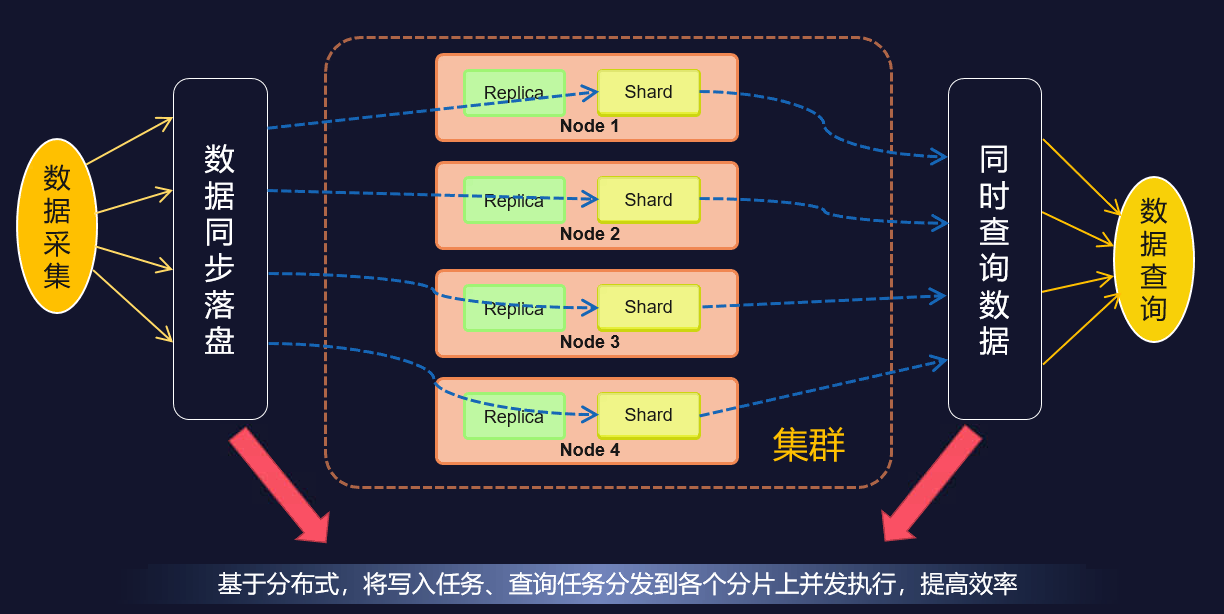 在海量日志新中快速检索所需信息,是定位问题的第一步。AnyRobot利用底层ElasticSearch作为搜索引擎,实现的百万数据量的秒
级检索,可以帮助用户快速定位关键信息,减少MTTRS。同时数据查询也是数据分析第一步,AnyRobot通过对系统海量数据查询分
析,帮助用户实现丰富的业务场景分析。
在海量日志新中快速检索所需信息,是定位问题的第一步。AnyRobot利用底层ElasticSearch作为搜索引擎,实现的百万数据量的秒
级检索,可以帮助用户快速定位关键信息,减少MTTRS。同时数据查询也是数据分析第一步,AnyRobot通过对系统海量数据查询分
析,帮助用户实现丰富的业务场景分析。
赞
点个赞吧!
请就本文对您的益处进行评级:










