AnyShare 就近访问特性浅析
一、背景
在多站点分布式部署场景,各站点数据都保存在本地对象存储,各站点间的带宽有限,如果数据统一在主站点处理,带宽压力大,主站点负载重,而分站点系统资源空闲,资源浪费。为了解决这些问题,需要把分站点数据处理放在站点内部处理,及就近处理,就近处理的优点:
1. 数据无传输到主站点,降低带宽占用,节省成本。
2. 降低对主站点的依赖和资源消耗,充分利用分站点资源,提升数据处理的效率,优化用户体验。
二、技术方案
就近处理通过采用监听数据上传的机制来提升处理的即时性,降低对上层业务服务的依赖,整体流程如下:1. OSS网关在完成对象上传到对象存储之后,提交“新对象上传”事件
2. 内容处理引擎收到“新对象上传”事件,识别对象类型,提交“内容处理任务”
3. 各内容处理服务接收到到任务后,开始对此对象进行内容处理
4. 处理完成,将内容处理结果通知到上层业务服务
三、就近访问原理
3.1 内容就近处理
内容就近处理包括杀毒、Office/PDF/CAD/音视频文件预览、加密、脱敏等功能,这些功能的特定是需要访问原始文件,并且处理后的数据需要就近保存到对象存储中。
分站点文档集完整的就近处理的逻辑如下:
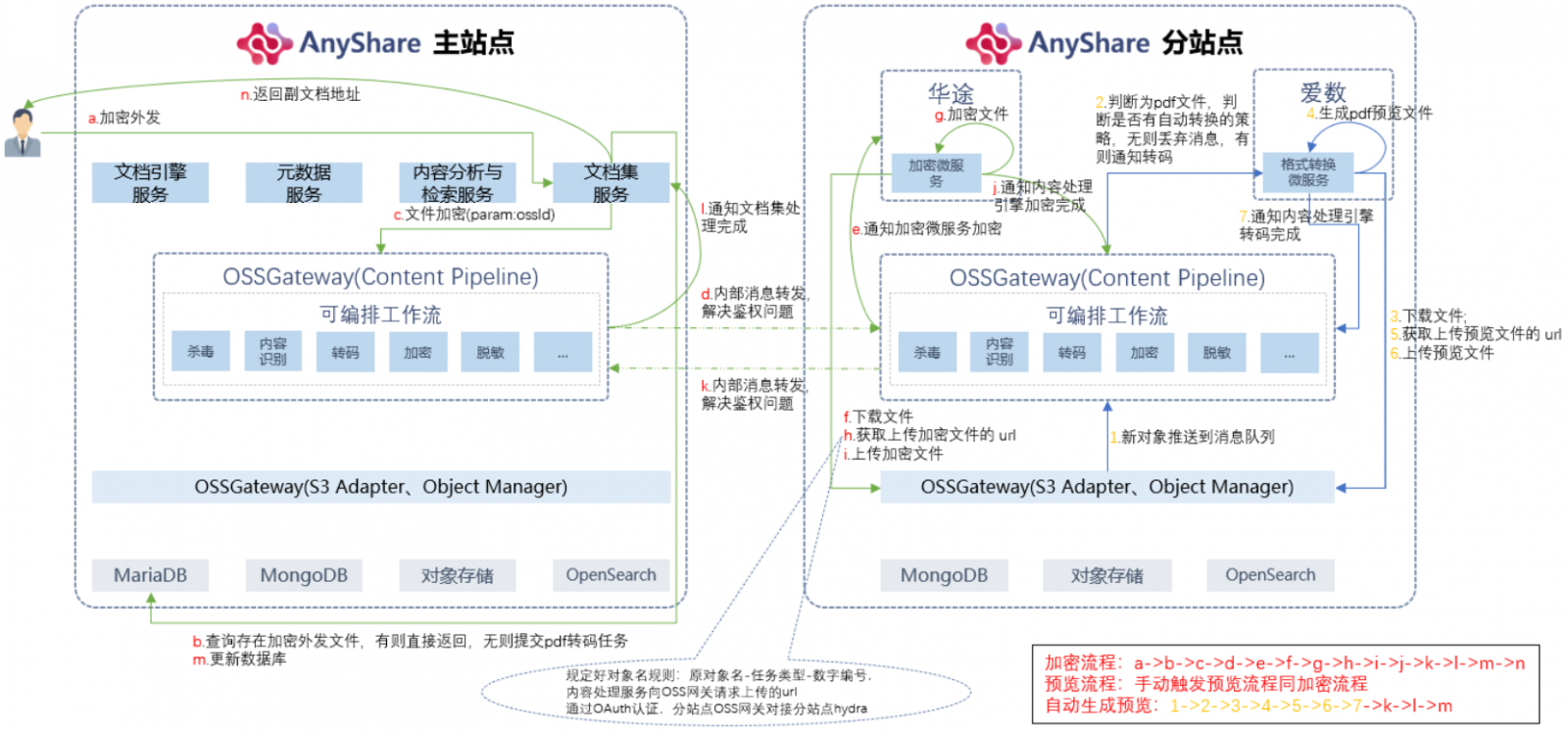
· 此逻辑覆盖实时生产触发、即时访问触发
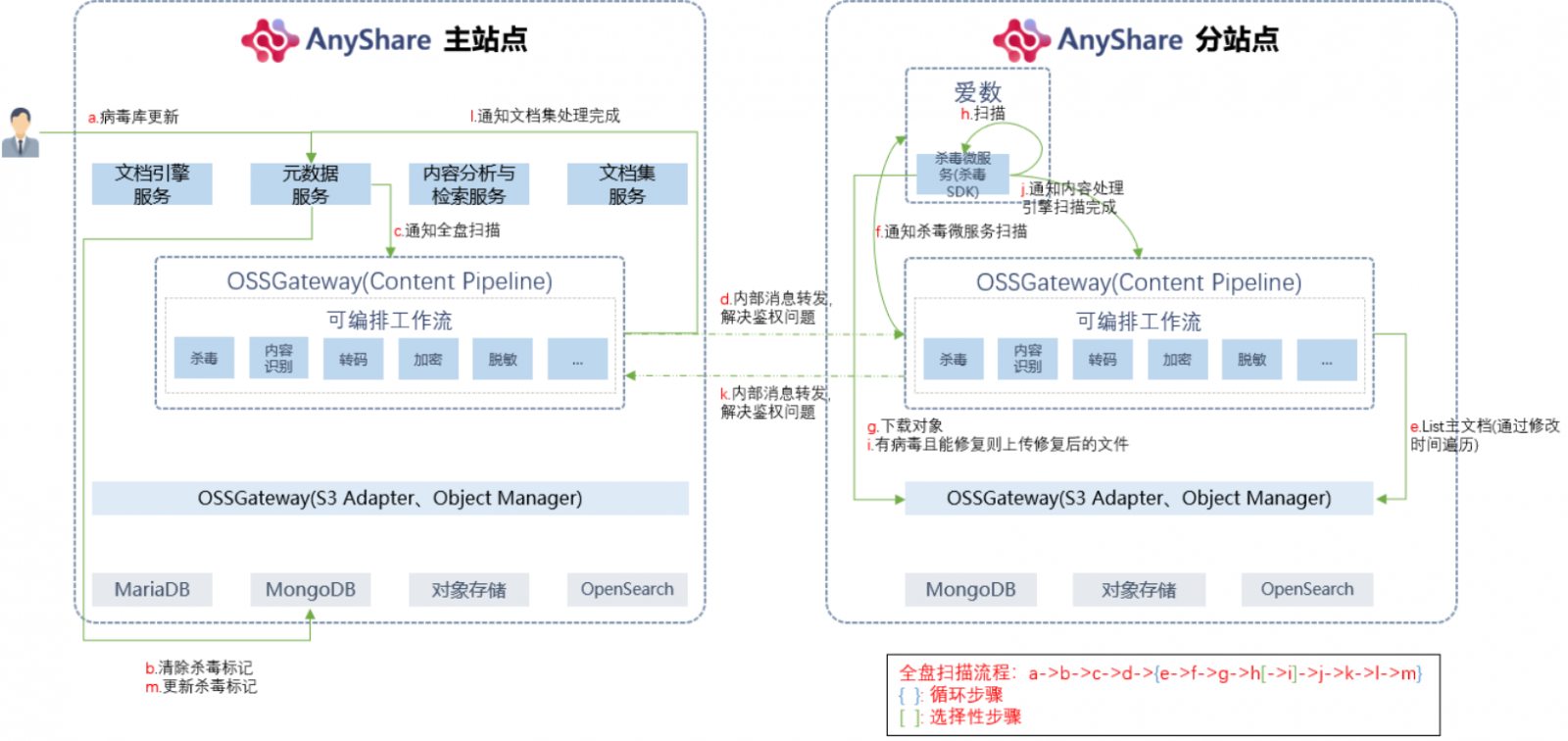 ·
· 此逻辑覆盖定时更新触发
· 为避免站点间过多的交互逻辑,由内容引擎负责站点间内容处理相关消息的交互。
· 内容处理引擎调度“加密未服务”、“格式转换服务”、“杀毒微服务”对要处理的对象进行处理,处理完之后通知主站点的文档集服务或者元数据服务,记录相关的信息
3.2 跨区域缓存
用户访问其他站点数据,需要经过网关将数据从其他资源站点拉取到本地站点,进行缓存,以达到跨站点互访加速目的。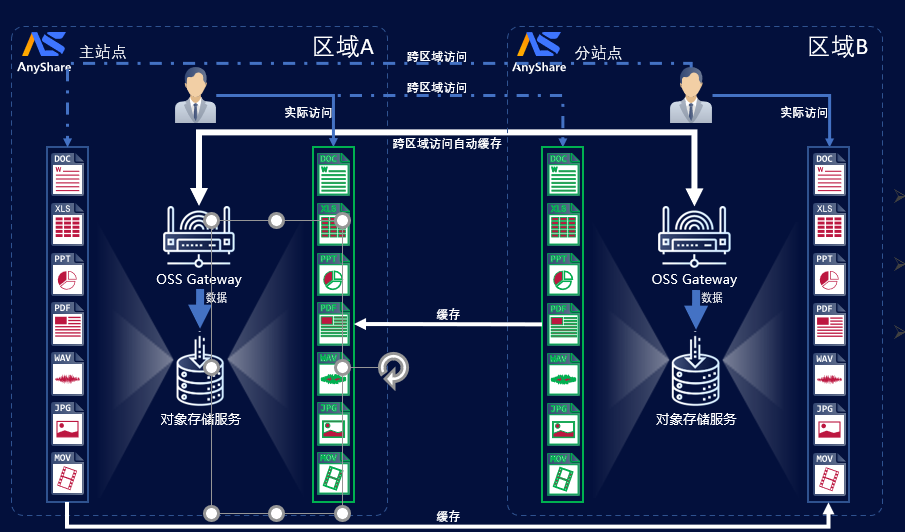
Ø 按需缓存:Bucket 级别的缓存配置,文件级粒度的缓存。
Ø 安全可控:访问本地缓存需 S3 标准鉴权。
Ø 灵活配置:可配置缓存时间、缓存数据量大小。
3.3 就近处理提升效果对比
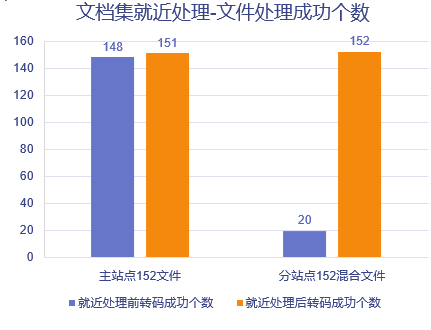
文档集性能对比
场景:多站点(主站点与分站点网络不同,均为内置存储)
无就近处理:主站点集群访问分站点存储网络较差,下载文件时建立连接超时,处理失败的文件多
有就近处理:分站点集群访问分站点存储网络好,文件处理效率与主站点相当
2,office online/wps online 性能对比
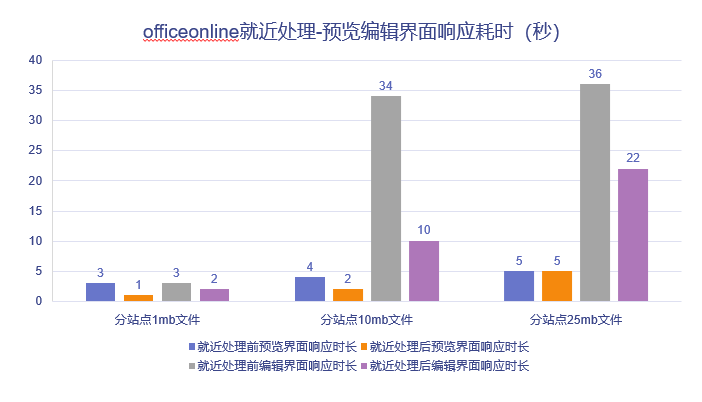
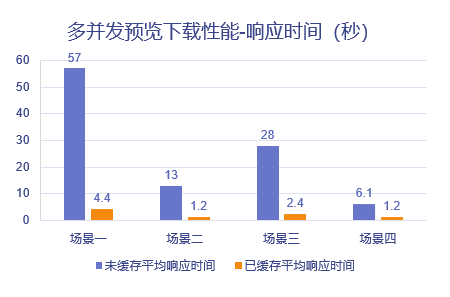
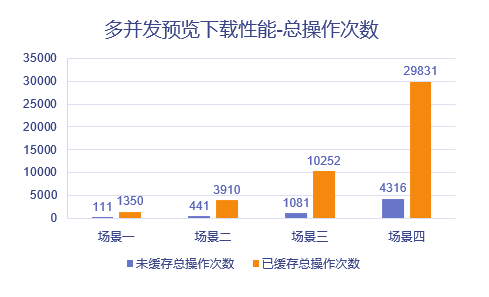
3,跨地域缓存性能对比
场景一:5分钟内20个主站点用户持续下载10mb分站点文件
场景二:5分钟内20个主站点用户持续预览10mb分站点文件
场景三:5分钟内100个主站点用户持续下载1mb分站点文件
场景四:5分钟内100个主站点用户持续预览1mb分站点文件
赞
点个赞吧!
请就本文对您的益处进行评级:










