Able 说 AI 丨大模型真的“大”吗?
万万没想到,ChatGPT参数只有200亿?
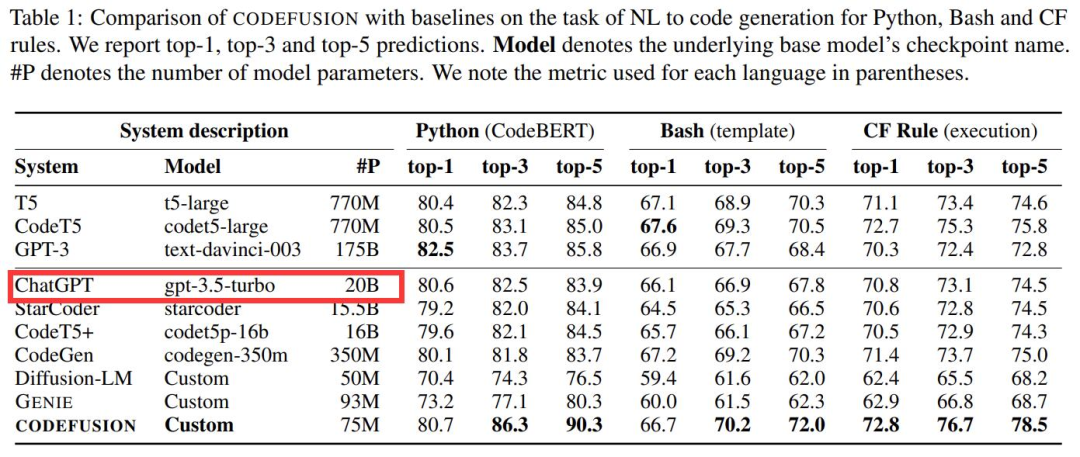
微软一篇题为《CodeFusion: A Pre-trained Diffusion Model for Code Generation》的论文,在做对比的时候透露出了重要信息:ChatGPT 是个「只有」20B(200 亿)参数的模型,这件事引起了广泛关注。
那,大模型真的还“大”吗?
当我们在谈论“大模型”的时候,实际上我们在谈论的是“大语言模型”。
点击下方视频,了解大模型的“大”到底是什么呢?
大模型是什么?
它是基于 transformer 架构及海量数据训练出来的语言模型,主要任务是根据上文预测下一个字或词。在这种情况下,大模型实际上是知识的一种压缩,它汇聚了大量的知识、文本和信息。
大模型是不是一定就很“大”?
当我们说“大模型”时,并不意味着它是一个绝对意义上的“大”。它的“大”是相对的。为什么说它“大”,是因为大语言模型只有到了一定规模,才能涌现出执行多任务的通用智能的能力。比如 Llama 模型,它是用了上千块的 GPU 花费几个月的时间训练出来的,参数量高达六百多亿。
大模型最大的特点是什么?
大语言模型的一个核心标志是 AGI,也就是“通用人工智能”能力。这是它与传统模型的一个关键区别。不同于传统的有限、专一的模型,AGI 具有更为广泛和深入的知识和判断能力,能够适应各种场景,提供多样的智能化能力。
大模型有了通用智能能力,可以做什么?
将通用智能能力植入到产品中去,将 AGI 技术作为我们产品平台未来的核心引擎。它的普适性、适应性和知识深度将为产品应用提供强大的支撑,更好为用户服务,满足用户经营决策需求。
“大模型”实际上代表着一个深入、广泛的知识压缩体,它有着 AGI 的核心能力,是人工智能时代产品应用的关键驱动力。
微软一篇题为《CodeFusion: A Pre-trained Diffusion Model for Code Generation》的论文,在做对比的时候透露出了重要信息:ChatGPT 是个「只有」20B(200 亿)参数的模型,这件事引起了广泛关注。
当我们在谈论“大模型”的时候,实际上我们在谈论的是“大语言模型”。
点击下方视频,了解大模型的“大”到底是什么呢?
大模型是什么?
它是基于 transformer 架构及海量数据训练出来的语言模型,主要任务是根据上文预测下一个字或词。在这种情况下,大模型实际上是知识的一种压缩,它汇聚了大量的知识、文本和信息。
大模型是不是一定就很“大”?
当我们说“大模型”时,并不意味着它是一个绝对意义上的“大”。它的“大”是相对的。为什么说它“大”,是因为大语言模型只有到了一定规模,才能涌现出执行多任务的通用智能的能力。比如 Llama 模型,它是用了上千块的 GPU 花费几个月的时间训练出来的,参数量高达六百多亿。
大模型最大的特点是什么?
大语言模型的一个核心标志是 AGI,也就是“通用人工智能”能力。这是它与传统模型的一个关键区别。不同于传统的有限、专一的模型,AGI 具有更为广泛和深入的知识和判断能力,能够适应各种场景,提供多样的智能化能力。
大模型有了通用智能能力,可以做什么?
将通用智能能力植入到产品中去,将 AGI 技术作为我们产品平台未来的核心引擎。它的普适性、适应性和知识深度将为产品应用提供强大的支撑,更好为用户服务,满足用户经营决策需求。
“大模型”实际上代表着一个深入、广泛的知识压缩体,它有着 AGI 的核心能力,是人工智能时代产品应用的关键驱动力。
赞
点个赞吧!
请就本文对您的益处进行评级:










