AnyDATA Framework 3.0.1.1 版本发布
AnyDATA Framework 3.0.1.1版本发布,更灵活的智能体应用创建!
【智能体工厂Agent Factory】
一、新增dolphin language简化复杂任务处理【智能体工厂Agent Factory】
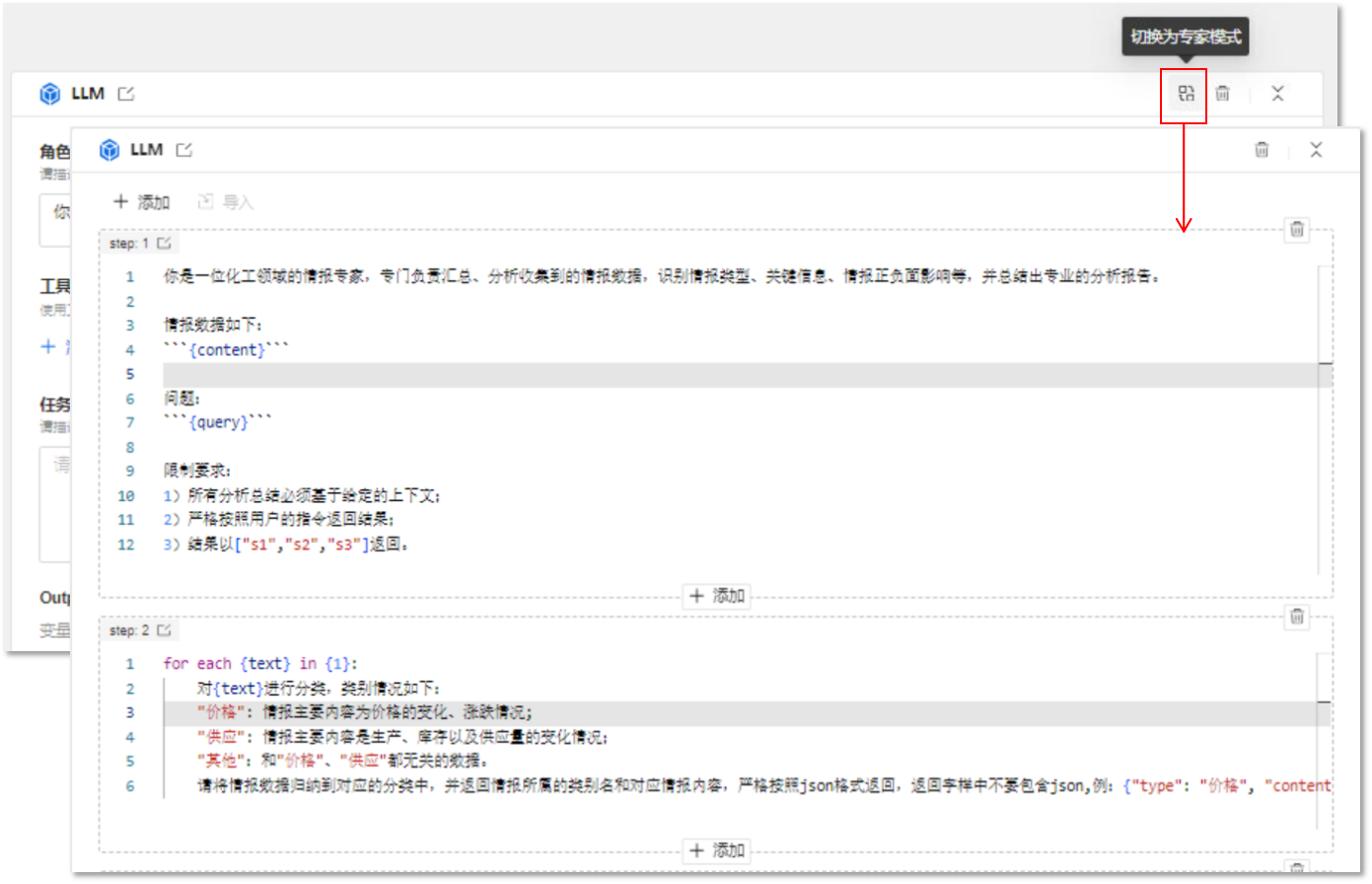
LLM块新增专家模式,支持用户通过自然语言描述任务,将复杂需求拆解为多个步骤,使大模型分步去完成相应的逻辑计算,从而在一个配置块中就高效完成了任务处理,不仅提升了处理复杂问题的能力,同时大大简化了应用配置。
二、支持多源异构数据丰富应用场景
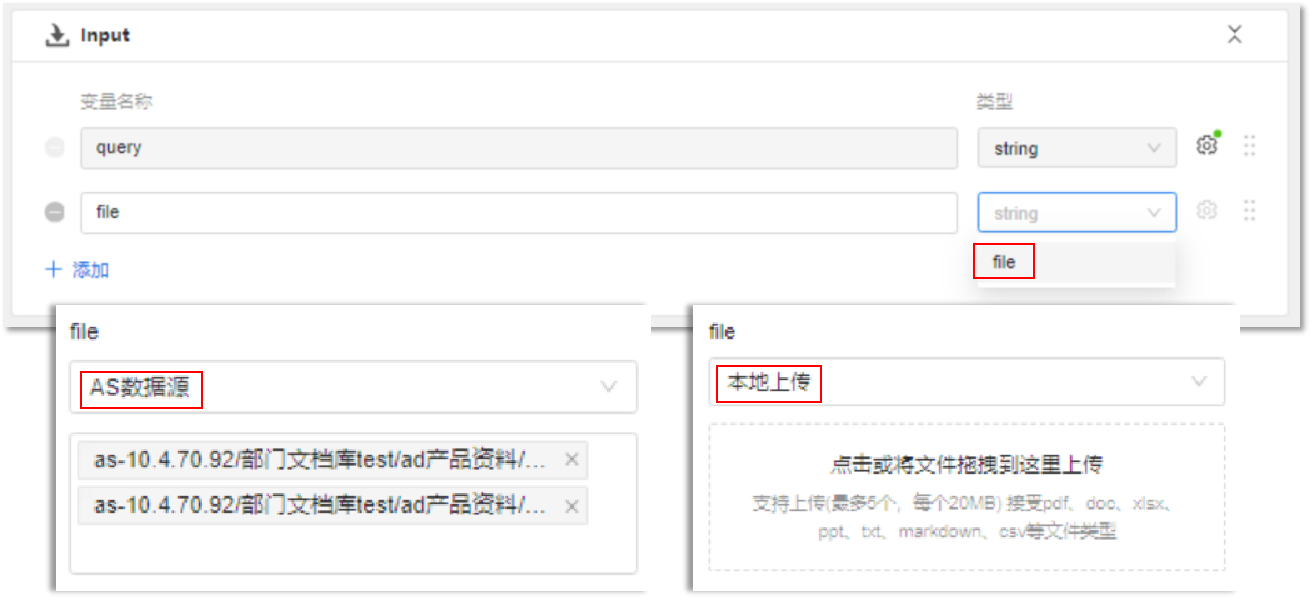
AnyDATA无缝对接AnyShare数据源,支持用户选择各类文件作为输入,包括但不限于doc、csv、ppt、pdf、markdown等格式,用户亦可轻松从本地直接上传文件,实现数据的即时调用,满足多样的业务需求,提升工作效率。
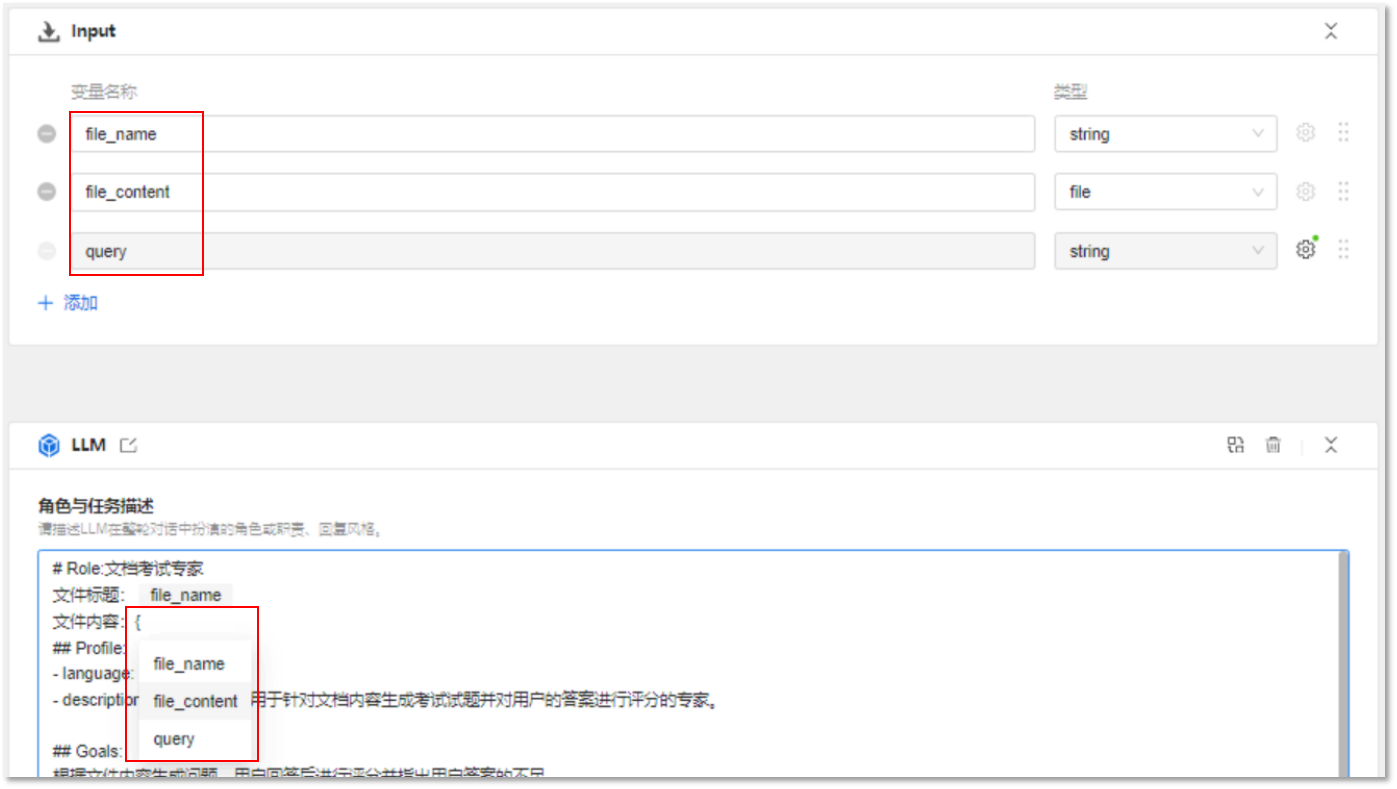
同时,用户可以创建多个不同类型的输入。例如创建一个基于文档的考试专家应用,用户不仅需要上传文档作为出题范围,还需要提供文档标题作为试题参考,这时通过添加多个输入项,并在提示词中加入对应参数,一旦用户完成输入,大模型便能迅速自动处理,返回用户满意的结果。
三、输入语句敏感信息检测
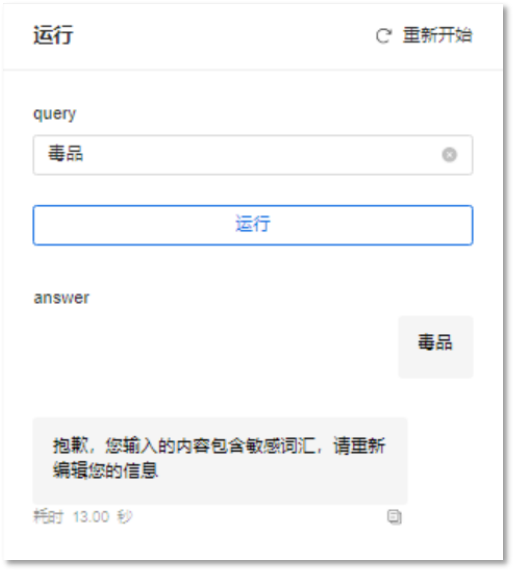
支持检测用户输入是否含有敏感信息,并实时回复提示,从而更好地保障信息安全和使用体验。
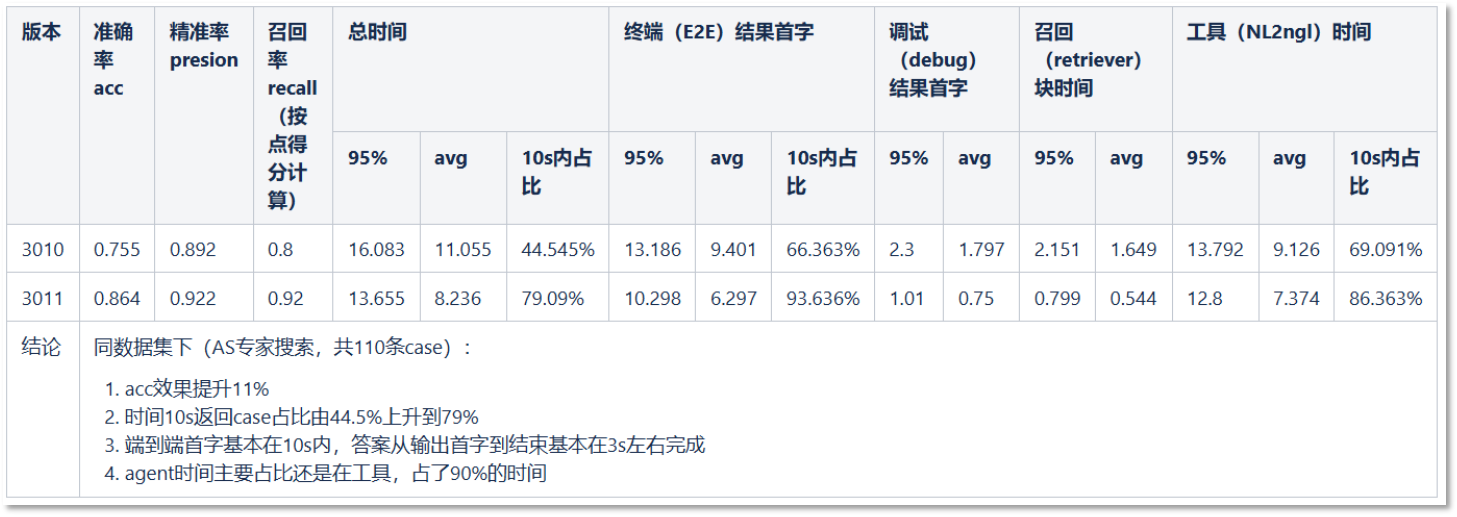
四、知识图谱问答性能优化
新版本优化了知识图谱数据召回逻辑,包括框架调优等,减少调用次数,缩短召回时间,提高召回精度,从而使大模型能够更快更准确地给出答案。
五、基于历史记录的问答优化
新版本支持保留大模型可支持的上下文长度范围内的对话内容,用户可以基于更多历史记录进行对话,同时历史记录的调用逻辑也进一步优化,为用户提供更快更准确的使用体验。
六、使用大模型进行知识抽取
支持运用大模型进行实体关系抽取,例如可以基于AnyShare内置图谱的本体,详细补充待抽取的实体类、关系类及其属性的描述,再通过构造提示词,调用大模型,对文档进行高效的结构化信息抽取,抽取后的数据将对应写入图谱中。如此,当用户进行搜索或问答时,就可以基于图谱中的对应关系,快速而精准的获取到所需答案。
【知识网络】
一、图概况数据量实时更新用户通过API更新图数据后,图概况会同步展示更新后的数据量,便于用户直观查看更新结果。
【模型工厂】
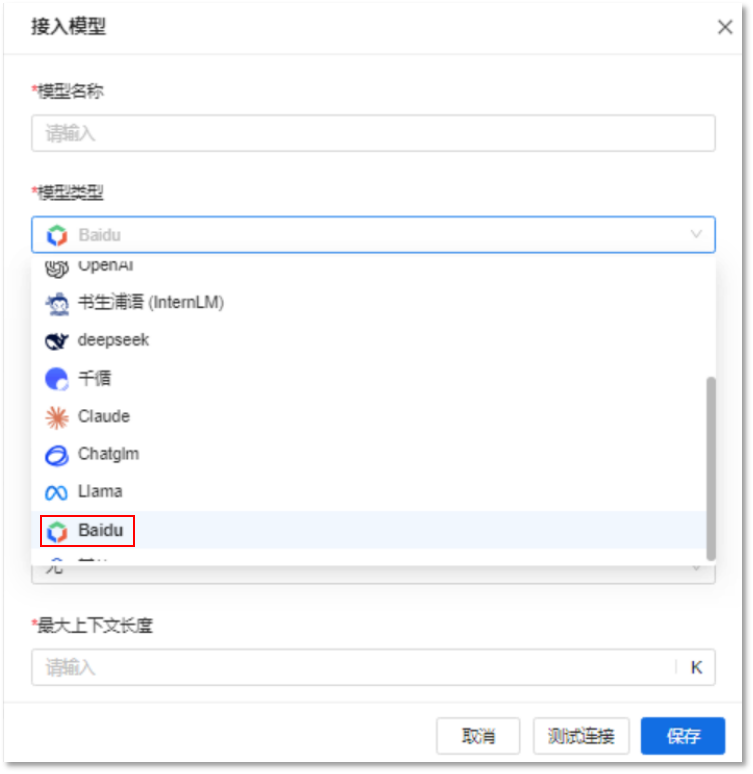
一、更丰富的大模型,拓宽应用场景新版本增加对百度大模型的支持,目前已支持接入多达数十种大模型,为用户提供了更多选择,灵活地选择适合需求的大模型。
【其他优化】
l AnyDATA内置大模型、以及小模型embedding 、reranker均支持适配华为昇腾300I Duo显卡,满足国产化部署模型的场景需求。l AnyDATA内置大模型、以及小模型embedding、reranker、SpeechModel、UIE均支持模块化部署,用户可以在部署工作台安装、配置、更新,从而更便捷地选择使用。
赞
点个赞吧!
请就本文对您的益处进行评级:










