

关于爱数
如何购买

> 10X
提升数据交付效率

60% 以上
节约数据管理成本

40% 以上
降低数据存算成本
VEGA 引擎是一款基于数据虚拟化技术构建的跨源、安全、高效的统一 SQL 查询引擎。通过 VEGA 引擎,用户可以对分布在不同数据源、数据中心以及执行引擎中的数据进行高效、灵活的统一查询与处理,从而提升数据访问的便捷性与处理效率。
VEGA 引擎通过 JDBC 协议连接各类数据源,实现数据的写入和取数,可实现跨源、跨中心的联邦查询和写入能力。
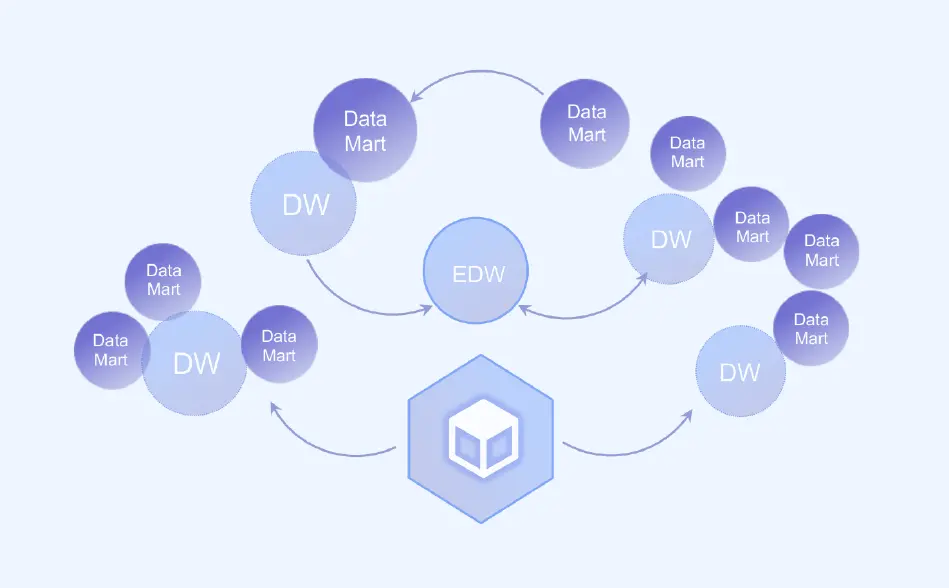
VEGA 引擎采用 SQL on Hadoop 的分布式处理存算分离架构,支持性能水平扩展提供 TB 级数据分析计算能力,秒级查询响应。同时支持各类数据源的查询加速策略。

VEGA 引擎为上层应用提供统一的数据访问接口,通过统一数据访问接口,数据应用开发人员能够更容易地访问多种异构数据源,而无需关注底层复杂的连接机制和协议。
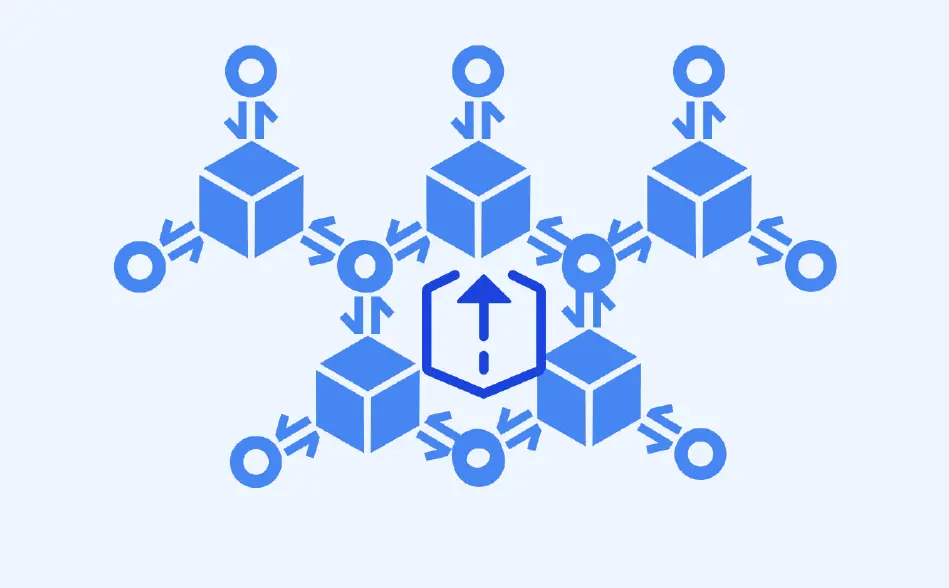

数据保留在其原始系统或数据架构中,并响应用户查询来访问这些数据。
利用先进的数据算子下推和缓存策略来缓解各类性能问题。
屏蔽不同数据源的语法差异,减少数据开发工程师的学习成本。

将 AnyFabric 产品动态直接发送到您的邮箱

立即咨询解决方案顾问,了解您的组织如何借助 AnyFabric 以数据提升生产力
选择订阅表示我同意接收爱数的 产品资讯以及相关动态。



版权所有 © 2006-2025 上海爱数信息技术股份有限公司 沪ICP备09089247号 沪公网安备 31011202011832
 语言选择
语言选择
选择订阅表示我同意接收爱数的 产品资讯以及相关动态。
语言选择
版权所有 © 2006-2025 上海爱数信息技术股份有限公司 沪ICP备09089247号 沪公网安备 31011202011832
选择订阅表示我同意接收爱数的 产品资讯以及相关动态。
语言选择
版权所有 © 2006-2025 上海爱数信息技术股份有限公司 沪ICP备09089247号 沪公网安备 31011202011832


扫码关注「爱数官方微信」

扫码关注「爱数服务号」
大数据基础设施领航者

抖音扫一扫 查看更多精彩视频
大数据基础设施领航者
请选择咨询类型
扫码关注
爱数技术支持中心公众号
我们将在 24 小时之内联系你。