


AnyDATA Framework 2.0.1.7版本发布
本次发布AnyDATA Framework 2.0.1.7版本,发布内容如下:
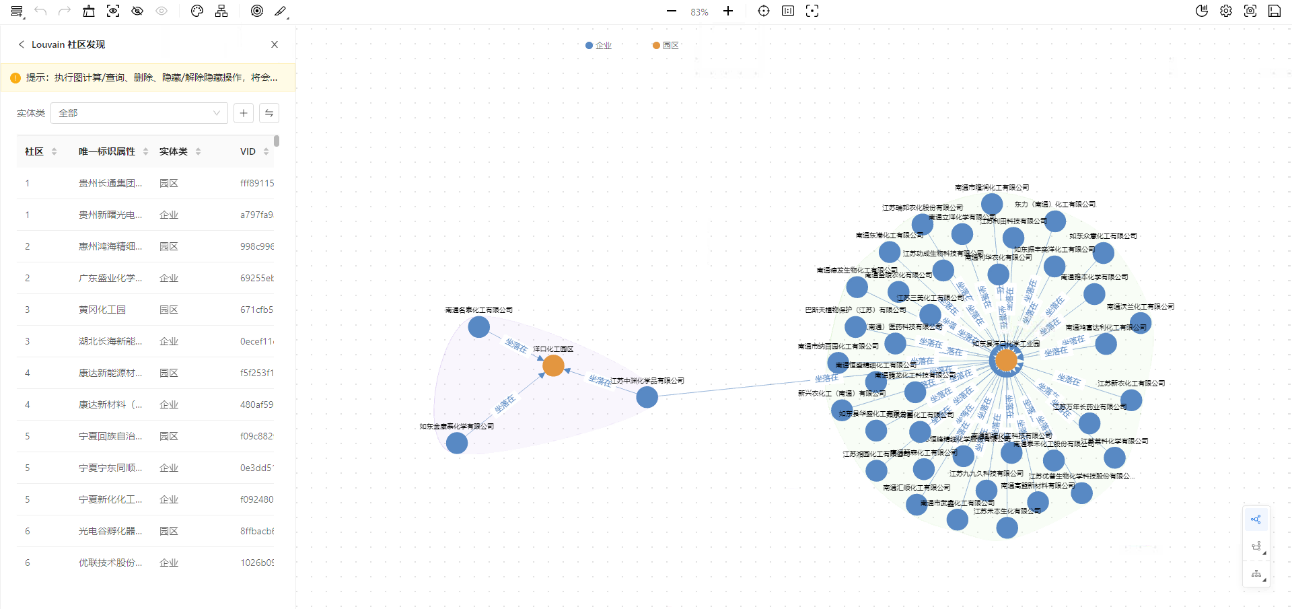
1、支持Louvain社区发现算法:发现网络中的隐藏社群
Louvain社区发现算法能够帮助用户更好地理解和分析图中的节点之间的联系和组织关系,从而发现数据中潜在的社区结构和群组。
2、支持完全版邻居查询:更加灵活的数据探索
邻居查询现支持配置关系拓展深度及搜索规则,通过灵活调整拓展深度和自定义搜索规则,帮助用户快速查询出符合特定条件的节点和关系。

3、支持图切片:保存关键数据,实现快速回溯
用户可以轻松地选中数据或图计算结果,并将其保存为图切片。图切片是对选中数据的快照,在之后的分析中可以快速添加到画布中,轻松回顾和比较之前的分析结果。避免重复操作,提高工作效率。

4、支持隐藏实体:聚焦图中的关键内容
支持自由选择实体和关系进行隐藏,让用户能够以更清晰和简洁的方式呈现和分析图数据。

5、图分析服务集成邻居查询:更灵活、高效的使用体验
邻居查询可以帮助您获取指定节点的邻居节点信息,从而更深入地了解节点之间的关系和连接。通过将邻居查询集成到图分析服务中,降低了服务配置门槛,提高查询效率,为
用户提供更加综合的图分析体验。


6、支持通过链接访问快照:快速访问和分享
支持通过简单的链接方式,直接访问PC端网页嵌入服务的快照。这一功能让用户能够更方便地快速访问和分享保存的快照内容。
快照链接可以在PC端网页嵌入说明文档中查看快照列表,点击需要应用的快照按钮获得。

7、交互体验优化
对部分场景下的交互进行了优化和升级,以提供更出色的用户体验和操作便捷性。包括:
(1) 支持选中图计算结果:
支持选中图计算结果,例如社区分析算法发现的其中一个社群,准确地定位和聚焦于感兴趣的图计算结果。
(2) 图分析服务配置布局将成为默认布局:
在配置阶段用户可以选择最适合需求的布局方式,使用服务时无需重复配置,节省了时间和精力。
(3) 图分析服务配置点边样式将成为默认样式:
在配置阶段用户所设定的样式将直接应用于服务中,既避免了重复操作,也确保了整个图分析过程中的样式的一致性。
(4)PC端网页嵌入配置项组件更灵活:
搜索、图语言查询、邻居查询等小组件功能既可以配置在顶部工具栏也可以配置在下拉框中,用户能根据自己的喜好和需求进行个性化的配置。
二、认知搜索服务:全新上线,体验精准搜索与无缝服务化
认知搜索服务是一种智能搜索服务,旨在提供更精准和个性化的搜索体验。本版本上线的认知搜索服务拥有以下关键功能:
1、认知搜索服务管理
用户可以方便地管理认知搜索服务,包括发布/取消发布、编辑、删除和测试服务等功能,实现对认知搜索服务的灵活管控。

2、认知搜索服务配置流程
认知搜索服务的配置流程包括以下几个部分:
(1)搜索资源配置:用户可以灵活地配置搜索所需的数据资源。
(2)搜索方式配置与测试:用户可以选择并配置符合需求的搜索方式。目前仅支持图谱全文检索,但用户可以根据需求配置搜索范围,以获取更加精准的搜索结果。此外,在配置完成后可以执行搜索服务测试,验证搜索结果的准确性和相关性。
(3)发布服务:用户可以进行服务相关权限和访问方式配置,并发布认知搜索服务。



3、意图管理
支持用户上传自己的数据集进行意图训练,目前训练的结果将在意图池中保存和管理。后续,我们将支持在认知搜索服务中集成意图,让服务将能够更好地理解用户的意图,提供更加个性化和精准的搜索结果。

三、知识网络生成之知识图谱构建:
1、拓展数据源选择
新增支持连接的数据源类型:PostgreSQL和人大金仓。

2、优化Hive数据处理性能
对于使用Hive数据源的用户,支持选择分区数据表。这意味着在处理大数据量时,可以有选择地操作特定分区,避免处理整个数据集时的繁琐和资源消耗。

3、领域智商计算性能优化
对领域智商计算性能进行了优化,提升大数据量下的计算速度,同时解决了多容器环境下可能出现的计算异常问题,保证了计算的稳定性和准确性。
4、支持自定义模型上传
引入了模型仓库的功能,允许用户上传和管理自己的模型,为后续功能的开发和应用提供了支持。

为用户提供更加便捷和准确的文档支持,避免手工编写文档可能带来的错误和不及时更新的问题。

图16 自动生成的API文档
【重大价值特性优化】
一、 图分析:释放数据潜力,图算法与邻居查询服务助力深层洞察1、支持Louvain社区发现算法:发现网络中的隐藏社群
Louvain社区发现算法能够帮助用户更好地理解和分析图中的节点之间的联系和组织关系,从而发现数据中潜在的社区结构和群组。
图1 Louvain社区发现示例
2、支持完全版邻居查询:更加灵活的数据探索
邻居查询现支持配置关系拓展深度及搜索规则,通过灵活调整拓展深度和自定义搜索规则,帮助用户快速查询出符合特定条件的节点和关系。
图2 完全版邻居查询
3、支持图切片:保存关键数据,实现快速回溯
用户可以轻松地选中数据或图计算结果,并将其保存为图切片。图切片是对选中数据的快照,在之后的分析中可以快速添加到画布中,轻松回顾和比较之前的分析结果。避免重复操作,提高工作效率。
图3 图切片
4、支持隐藏实体:聚焦图中的关键内容
支持自由选择实体和关系进行隐藏,让用户能够以更清晰和简洁的方式呈现和分析图数据。
图4 隐藏实体
5、图分析服务集成邻居查询:更灵活、高效的使用体验
邻居查询可以帮助您获取指定节点的邻居节点信息,从而更深入地了解节点之间的关系和连接。通过将邻居查询集成到图分析服务中,降低了服务配置门槛,提高查询效率,为
用户提供更加综合的图分析体验。
图5 选择邻居查询搜索方式
图6 邻居查询策略配置
6、支持通过链接访问快照:快速访问和分享
支持通过简单的链接方式,直接访问PC端网页嵌入服务的快照。这一功能让用户能够更方便地快速访问和分享保存的快照内容。
快照链接可以在PC端网页嵌入说明文档中查看快照列表,点击需要应用的快照按钮获得。
图7 PC端网页嵌入说明文档
7、交互体验优化
对部分场景下的交互进行了优化和升级,以提供更出色的用户体验和操作便捷性。包括:
(1) 支持选中图计算结果:
支持选中图计算结果,例如社区分析算法发现的其中一个社群,准确地定位和聚焦于感兴趣的图计算结果。
(2) 图分析服务配置布局将成为默认布局:
在配置阶段用户可以选择最适合需求的布局方式,使用服务时无需重复配置,节省了时间和精力。
(3) 图分析服务配置点边样式将成为默认样式:
在配置阶段用户所设定的样式将直接应用于服务中,既避免了重复操作,也确保了整个图分析过程中的样式的一致性。
(4)PC端网页嵌入配置项组件更灵活:
搜索、图语言查询、邻居查询等小组件功能既可以配置在顶部工具栏也可以配置在下拉框中,用户能根据自己的喜好和需求进行个性化的配置。
二、认知搜索服务:全新上线,体验精准搜索与无缝服务化
认知搜索服务是一种智能搜索服务,旨在提供更精准和个性化的搜索体验。本版本上线的认知搜索服务拥有以下关键功能:
1、认知搜索服务管理
用户可以方便地管理认知搜索服务,包括发布/取消发布、编辑、删除和测试服务等功能,实现对认知搜索服务的灵活管控。
图8 认知搜索服务操作
2、认知搜索服务配置流程
认知搜索服务的配置流程包括以下几个部分:
(1)搜索资源配置:用户可以灵活地配置搜索所需的数据资源。
(2)搜索方式配置与测试:用户可以选择并配置符合需求的搜索方式。目前仅支持图谱全文检索,但用户可以根据需求配置搜索范围,以获取更加精准的搜索结果。此外,在配置完成后可以执行搜索服务测试,验证搜索结果的准确性和相关性。
(3)发布服务:用户可以进行服务相关权限和访问方式配置,并发布认知搜索服务。
图9-图11 认知搜索服务配置流程
3、意图管理
支持用户上传自己的数据集进行意图训练,目前训练的结果将在意图池中保存和管理。后续,我们将支持在认知搜索服务中集成意图,让服务将能够更好地理解用户的意图,提供更加个性化和精准的搜索结果。
图12 意图训练
三、知识网络生成之知识图谱构建:
1、拓展数据源选择
新增支持连接的数据源类型:PostgreSQL和人大金仓。
图13 新增数据源类型
2、优化Hive数据处理性能
对于使用Hive数据源的用户,支持选择分区数据表。这意味着在处理大数据量时,可以有选择地操作特定分区,避免处理整个数据集时的繁琐和资源消耗。
图14 Hive数据源分区配置
3、领域智商计算性能优化
对领域智商计算性能进行了优化,提升大数据量下的计算速度,同时解决了多容器环境下可能出现的计算异常问题,保证了计算的稳定性和准确性。
4、支持自定义模型上传
引入了模型仓库的功能,允许用户上传和管理自己的模型,为后续功能的开发和应用提供了支持。
图15 导入模型
【其他新增功能或优化】
一、自动生成API文档为用户提供更加便捷和准确的文档支持,避免手工编写文档可能带来的错误和不及时更新的问题。
图16 自动生成的API文档
赞
点个赞吧!
请就本文对您的益处进行评级:










