


AnyShare Family 7 同步盘探测原理解读
探测机制的介绍
1. 什么是同步盘?
通过同步盘,可建立同步盘内文件夹和本地文件夹之间的同步关系。同步盘内的文件发生变化或本地的文件发生变化,同步盘会自动在另一端同步更新文件,保证同步盘内和本地的文件的一致性。通过同步盘,可以将本地的文件实时自动备份到AnyShare云端,也可以实时获得AnyShare云端内最新的文件内容,保证与他人的实时协作沟通。
2.同步盘为什么要引入探测机制?
引入探测机制,是为了本地能够实时获得同步盘内最新的文件内容,保证与他人的实时协作沟通。
3.什么是探测机制?
同步盘为了获取云端的最新文件内容,保证本地数据与云端数据的一致性,同步盘采用不断轮询方式,向服务端请求获取文件信息,然后与本地数据库存储的信息进行比对,从而判断出云端哪个文件发生了变化,更新本地文件。
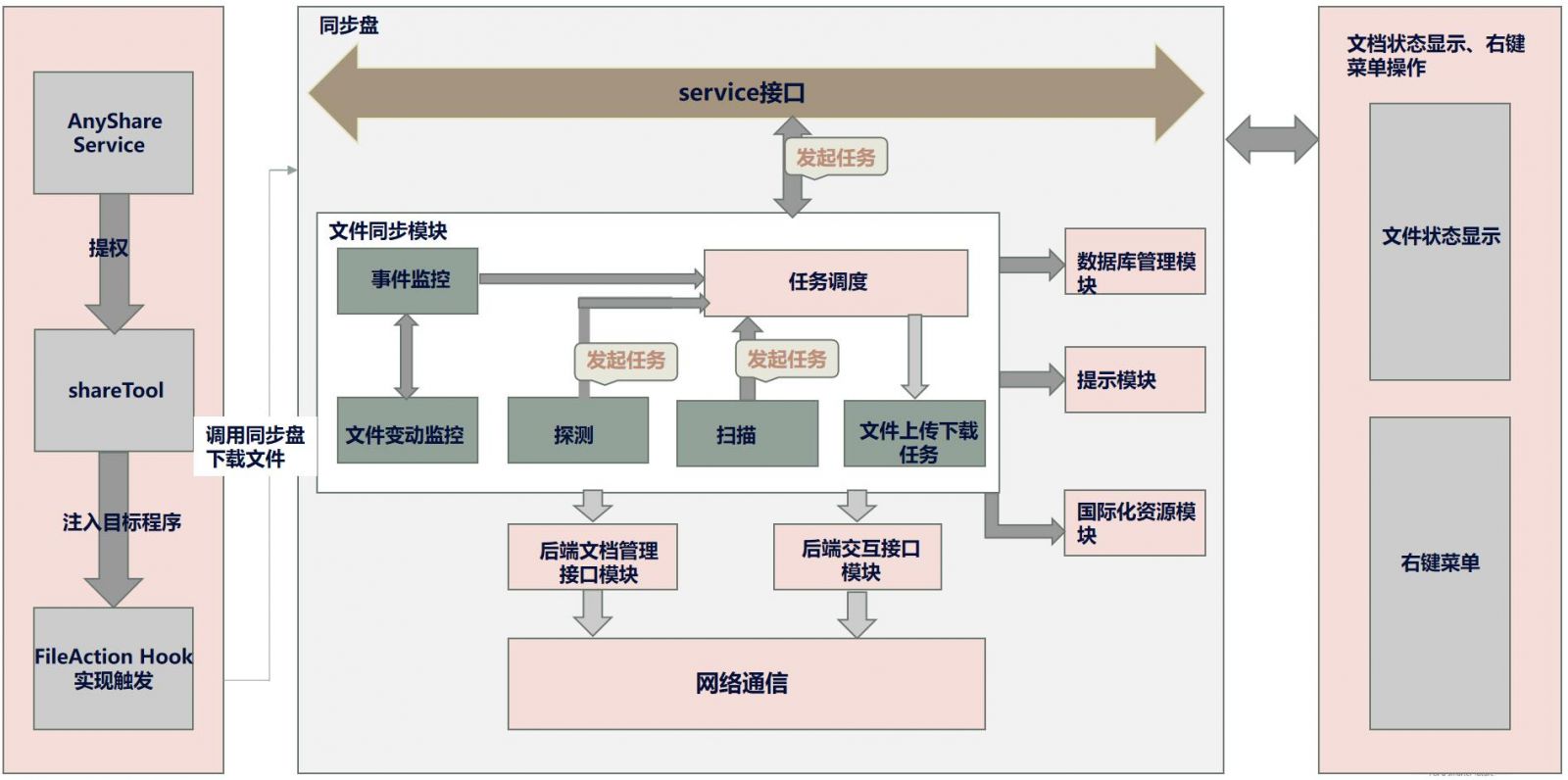
同步盘的整体架构
探测机制的使用场景
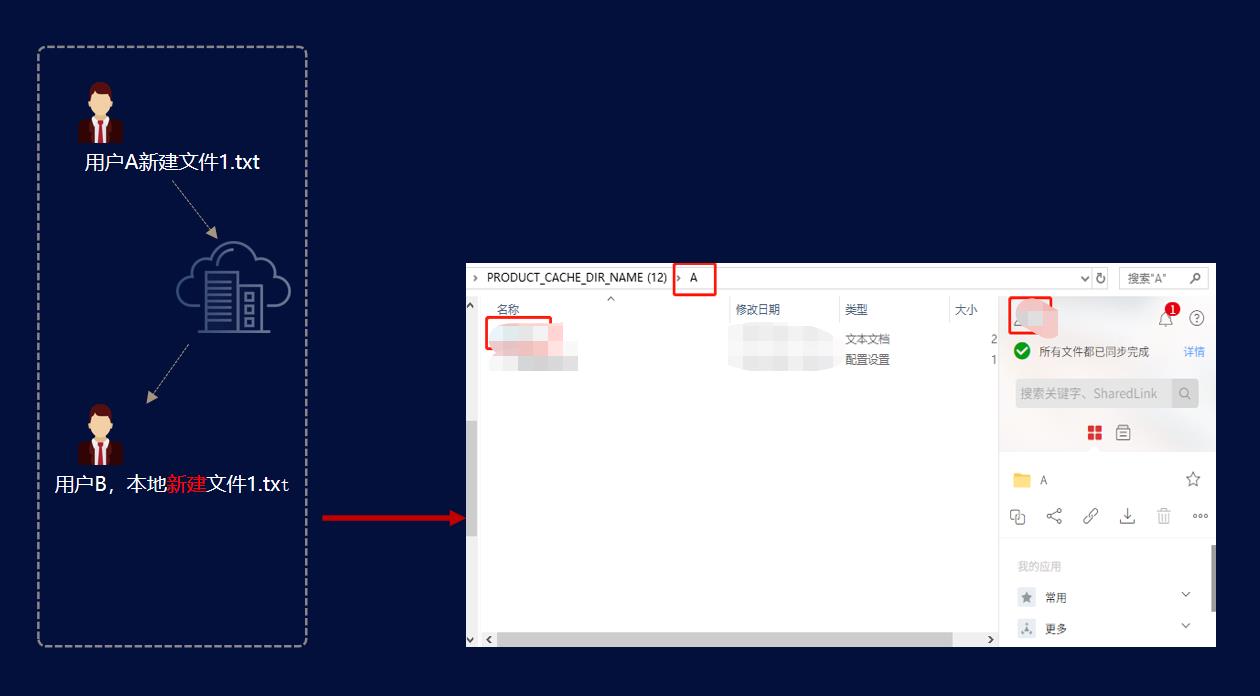
场景一:云端新建/删除文件(夹)
说明:
用户 A 已共享用户 B A 目录
用户 B 已缓存 A 目录
用户 A 在 A 目录下新建 1.txt, 用户 B 如何感知到 A 目录下新建了 1.txt?
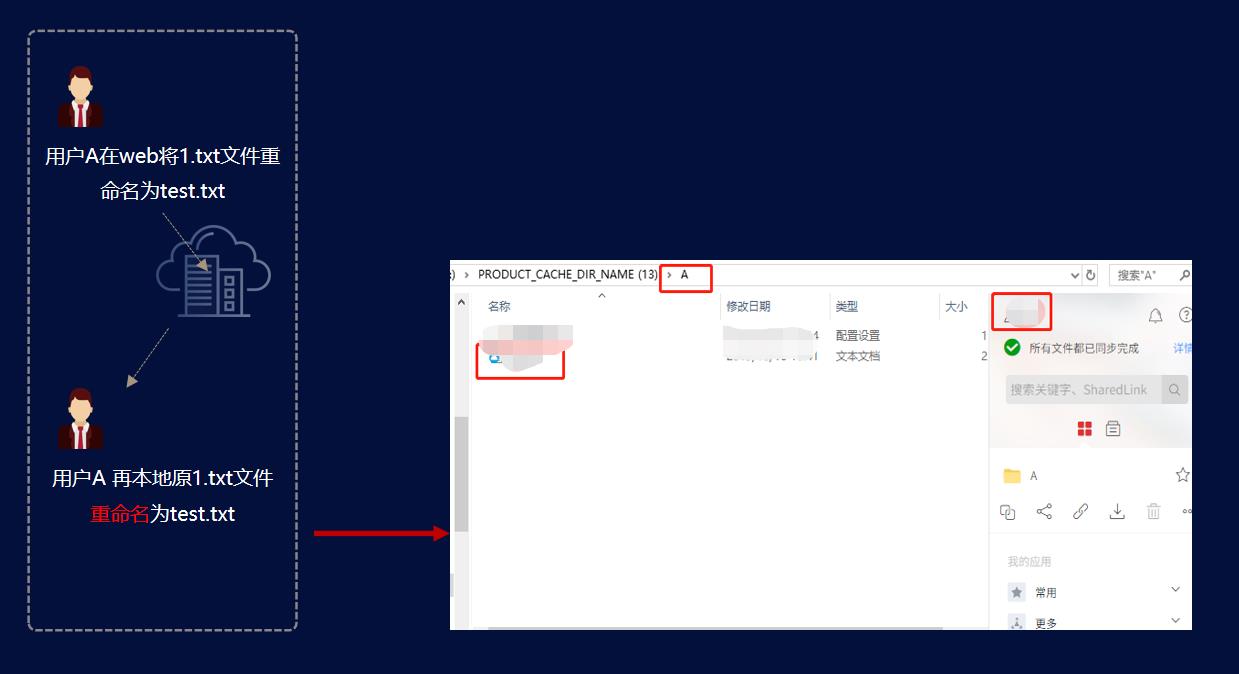
场景二:云端文件属性修改(名字、修改时间、水印、权限、锁状态等)
说明:
用户 A 本地可看到 1.txt文件
用户 A 在 web 端重命名 1.txt 为 test.txt
客户端如何感知此时 A 盘内的 1.txt 名字需要更新为 test.txt?
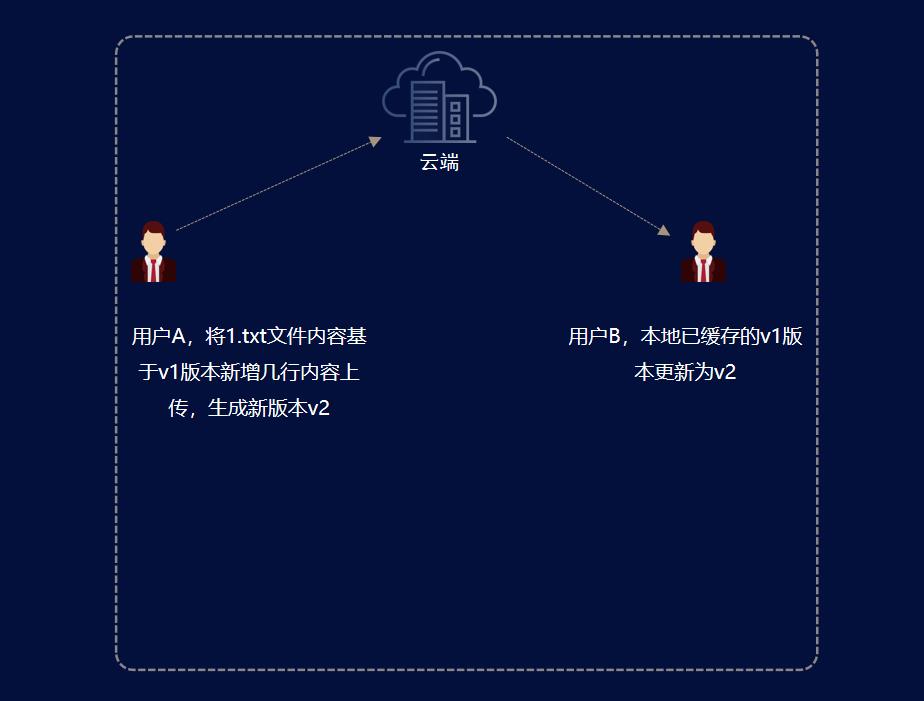
场景三:云端文件内容修改(已缓存的过期文件、自动更新的文件)
说明:
用户 A 已共享用户 B,1.txt 用户 B 本地已缓存 1.txt 的 v1 版本。
此时用户 A 基于 1.txt 的 v1 版本修改上传生成新版本 v2
那么客户端如何感知此时的 B 盘内已缓存的 1.txt 是过期文件呢?
探测机制的实现原理
探测算法:
- 获取本地数据库信息 map1(按 docid 排序)
- 获取云端数据库信息 map2(按 docid 排序)
- 比较 map1 和 map2,若本地有,云端无,
- 若是目录,则向下删除目录;(数据库、数据)
- 若是文件,则向下删除文件;(数据库、数据)
- 若本地无,云端有,
- 若是目录,则向下新建目录;(数据、数据库)
- 若是文件,则向下新建文件;(数据、数据库)
- 若本地有,云端有,
- 若是目录,
- 若名字不同,则向下重命名目录;(数据、数据库)
- 若 attr 不同,则向下更新 attr;(数据库)(并探测该目录)
- 若 servertime 不同,则向下更新 servertime;(数据库)
- 若 otag 不同,则向下更新 otag;(数据库)(并探测该目录)
- 若 watermark 不同,则向下更新 watermark;(数据库)
- 若 typename 不同,则向下更新 typename;(数据库)
- 若是文件,
- 若名字不同,则向下重命名文件;(数据、数据库)
- 若 attr 不同,则向下更新 attr;(数据库)
- 若 servertime 不同,则向下更新 servertime;(数据库)
- 若 otag 不同,则向下更新 status;(数据流、数据库)
- 若文件过期,则向下更新文件状态伟过期;
- 若是目录,
总结:
为保证本地与云端的数据一致,采用一种根据 otag 为标识的同步云端数据至本地的机制。
每个对象(文件或目录)都有一个 otag,如果对象本身或者对象中的子对象产生变化(文件发生修改或目录下有新增修改等)则 otag 更新;客户端定时轮询比对云端和本地数据库 otag 的值,若 otag 不一致则认定云端数据发生过变化,此时会把云端数据更新下来。
说明:
探测入口分为主缓存入口和本地同步目录入口,各入口分别有自己对应的探测队列。 其中有需要优先探测的目录,使用内联探测,由于内联探测与主探测非同一线程,故同样拥有独立的探测队列,不需要跟主缓存共用同一个队列,这样就使得使用内联探测的目录无需等待队列中已有的目录先执行。
探测模式
探测机制会根据探测模式来判断是否要继续往下探测,探测分为以下几种模式:
延迟模式:探测时跳过延迟下载的目录,并对新增对象进行延迟下载(默认)。
策略模式:探测时检查延迟下载策略,并根据策略对新增对象进行对应下载(自动下载)。
完整模式:探测时不跳过延迟下载目录,并对新增对象进行完全下载(立即下载)。
自动缓存目录树模式:探测时对设置了该策略的目录,下载目录树结构(自动下载目录树结构)。
自动更新过期文件模式:探测时对设置了该策略的目录,主动下载过期文件的最新版本(自动下载过期文件)。
探测产生的任务
1.向下创建文件/文件夹
2.向下删除文件/文件夹
3.向下编辑文件
4.向下重命名文件/文件夹
5.向下更新文件/文件夹属性
6.向下更新延迟下载标记(delay 数据流)
7.向下更新文件夹的修改时间
8.向下更新 otag
9.向下更新文档库类型
10.向下更新水印信息
请就本文对您的益处进行评级:










