


Hadoop备份恢复原理解析
早在2016年IDC就预测,全球大数据市场将达170亿美元规模,市场发展前景很大。而Hadoop作为新一代的架构和技术,因为有利于并行分布处理 “大数据”而备受重视。Hadoop分布式文件系统(Hadoop Distributed File System)能提供高吞吐量的数据访问,适合大规模数据集方面的应用,为海量数据提供存储服务,提供类POSIX接口。
Hadoop的核心组件
Hadoop的核心组件是MapReduce和HDFS,MapReduce是一种编程模型,用于大规模数据集的并行运算。Map(映射)和Reduce(化简),采用分而治之思想,先把任务分发到集群多个节点上,并行计算,然后再把计算结果合并,从而得到最终计算结果。HDFS是一个高度容错性的分布式文件系统,能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。

Hadoop分布式文件系统(Hadoop Distributed File System)能提供高吞吐量的数据访问,适合大规模
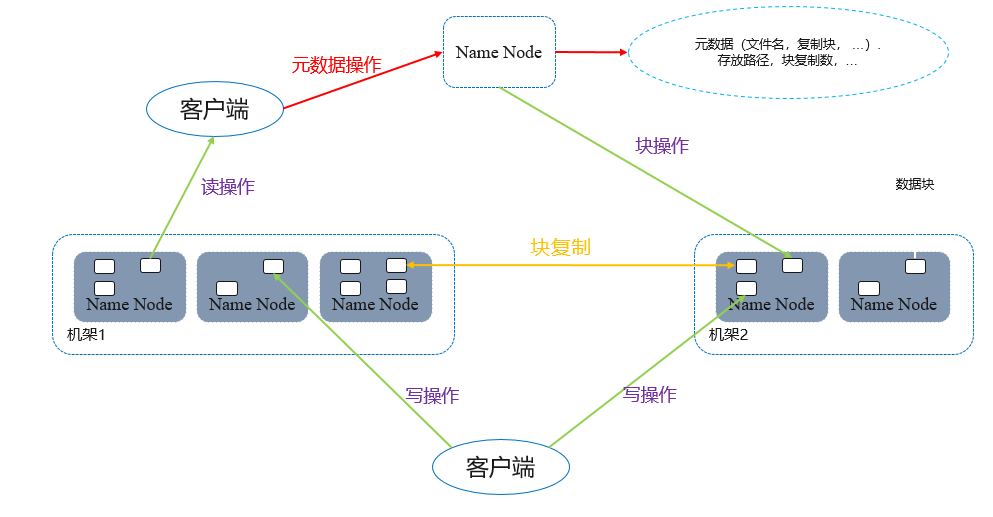
在HDFS内部,一个文件分成一个或多个“数据块”,这些“数据块”存储在DataNode集合里,NameNode负责保存和管理所有的HDFS元数据。客户端连接到NameNode,执行文件系统的“命名空间”操作,例如打开、关闭、重命名文件和目录,同时决定“数据块”到具体DataNode节点的映射。DataNode在NameNode的指挥下进行“数据块”的创建、删除和复制。客户端连接到DataNode,执行读写数据块操作。
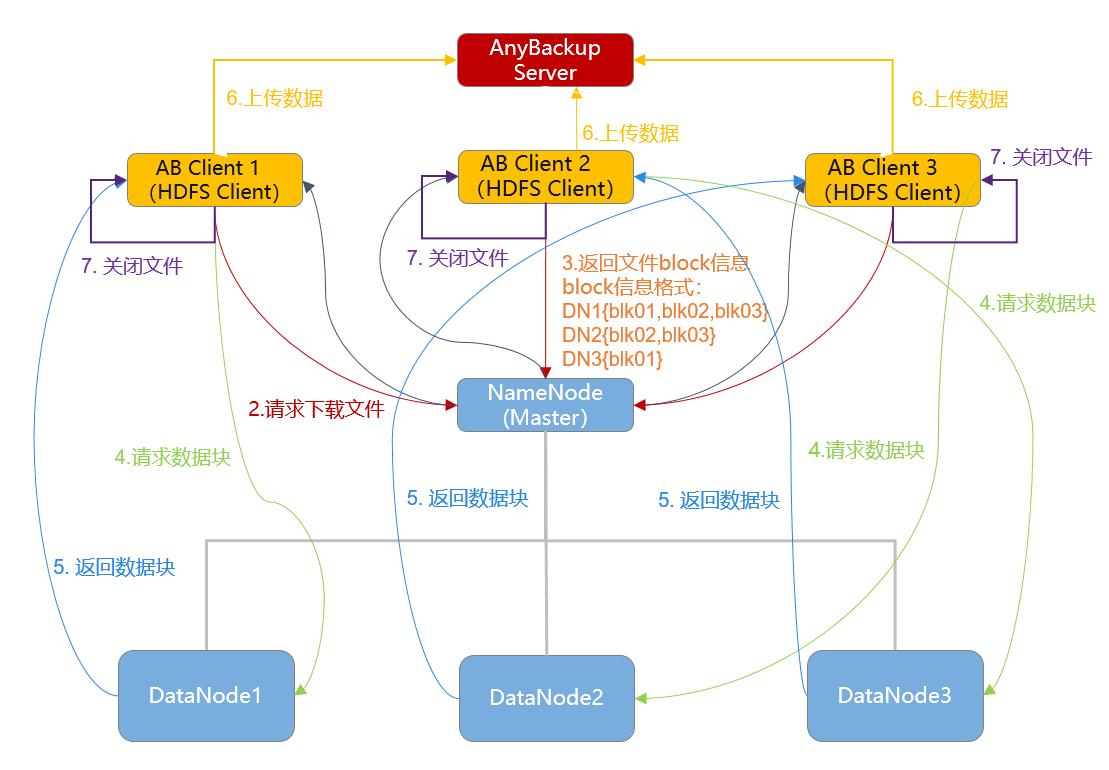
备份流程
(以3个AnyBackup Client 为例):
1.发起备份,相关HDFS节点上的AnyBackup Client执行进程启动,解析备份数据源、备份类型等。
2.执行进程(后称 hdfsclient )请求下载文件,将需要备份的数据对象传递给NameNode 。
3.NameNode返回文件block信息。 (输入流FSDataOutputStream对象与NameNode建立连接,通过RPC getBlockLocations () 确定文件block的保存位置,即DataNode 地址 ;不会一次返回文件所有的block信息,需多次调用getBlockLocations () )
4.hdfsclient解析NameNode返回的备份对象元数据,获取文件block的位置信息,和最近的DataNode建立连接并下载文件block。
5.NameNode返回文件block, hdfsclient读取文件block之后验证DataNode中的校验和,保证数据的一致性。
6.Client发送备份数据至AnyBackup Server。
7.一直重复操作4 5 6,逐一备份文件block,直至所有block全部备份完成, hdfsclient关闭输入流FSDataOutputStream对象,以示文件下载并备份完成。
8.一直重复操作2 3 4 5 6 7,逐一下载并备份文件/目录,直至所有文件/目录全部下载并备份完成,即备份结束。
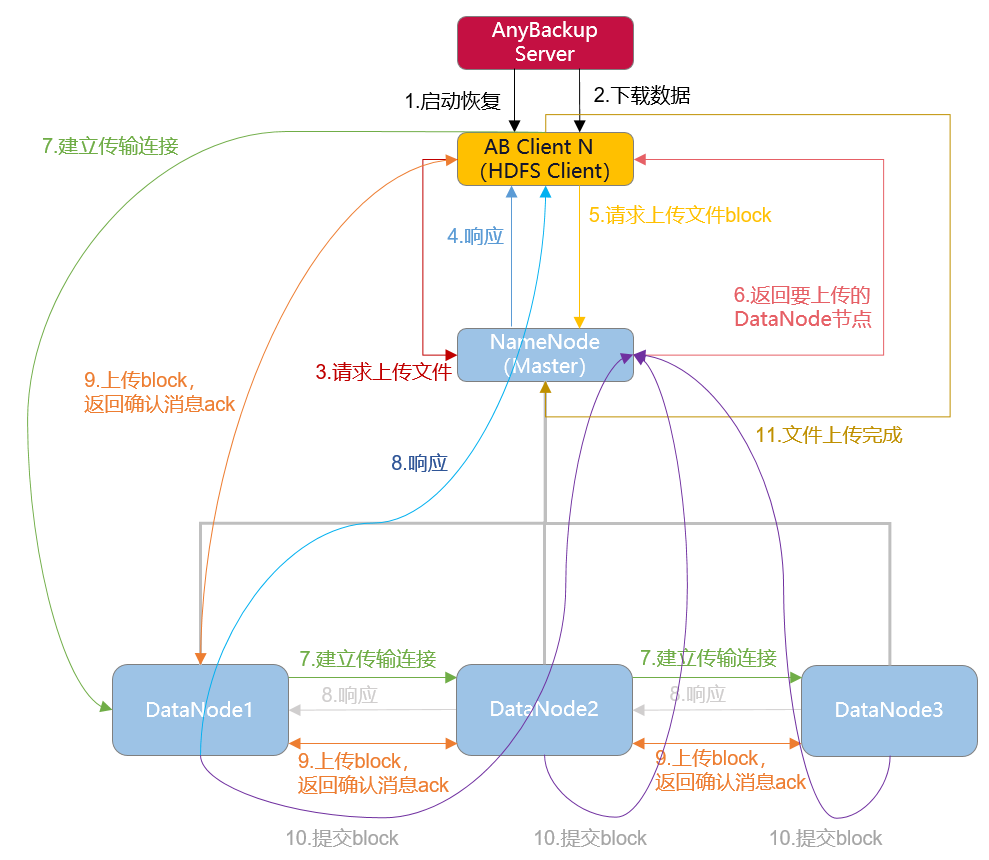
 恢复流程
恢复流程(以单个AnyBackup Client 为例):
1.发起恢复,相关HDFS节点上的AnyBackup Client执行进程启动。
2.执行进程 从备份存储中下载待恢复对象,
3.执行进程(后称 hdfsclient )跟NameNode通信请求上传文件。
4.NameNode检查检查目标文件是否存在,hdfsclient是否有其父目录中创建文件的权限。若检查通过,则NameNode构造名为file.copying的临时文件,并返回可以上传。
5.hdfsclient向NameNode请求上传文件的第一个block。
6.NameNode返回DataNode信息,表明该block应传输到哪些DataNode上。
7.hdfsclient与第一个DataNode建立pipeline (RPC调用),第一个DataNode再与第二个DataNode建立pipeline ,然后第二个DataNode再与第二个DataNode建立pipeline,直到整个pipeline建立完成。
8.pipeline建立后,按照建立顺序的逆序逐级响应,最后通知hdfsclient。
9.hdfsclient开始上传block,并逆序返回确认消息ack。
10.每个block上传完成后, DataNode向NameNode提交信息,以示该block上传完成。
11.一直重复操作第5、6、7、8、9、10步,逐一上传block ,直至所有block全部上传完成, hdfsclient通知NameNode关闭文件,NameNode将该文件的.copying后缀去掉,文件上传完成。
12.一直重复操作第2、3、4、5、6、7、8、9、10、11步,逐一上传文件/目录,直至所有文件/目录全部上传完成,即恢复结束。
利用Hadoop HDFS Client 提供的接口来完成备份恢复功能,具有如下优点:
- 提供文件/目录级别的细粒度备份和恢复
- 支持完全备份、增量备份、永久增量备份、差异备份
- 支持原HDFS、异HDFS恢复,支持恢复到Linux常见的文件系统(XFS、Ext4、Ntfs)
- 多节点并发,节点内多线程读/写数据,提高备份/恢复速度,缩小备份/恢复窗口
- 可根据环境配置,进行数据校验和加密,保证数据传输的安全性(HDFS端->HDFS Client端数据传输加密)
- 支持远程复制,异地容灾,提高数据的保护等级
- 支持重删、压缩、加密、远程复制高级特性,减少数据传输和存储空间,提供存储空间的利用率
- 备份时支持根据文件路径、时间等属性的过滤条件,筛选备份对象
赞
点个赞吧!
请就本文对您的益处进行评级:










