


AnyShare Family 7 相似搜索结果折叠技术解析
传统搜索结果排序所有的文档使用相同的优先级判断算法,被搜索范围内,包含相似、相同文档的情况下,会在结果中排在一起,文档搜索包含大量重复结果,导致使用体验差。AnyShare Family 7 通过文档指纹生成算法技术实现了相似搜索结果折叠的功能,本文我们将对此技术进行相关解析。
part 1 - 效果展示对比
通过下面的示例我们可以看出,在使用相似搜索结果折叠的情况下,可以更为直观快速的定位到我们需要寻找的文档。
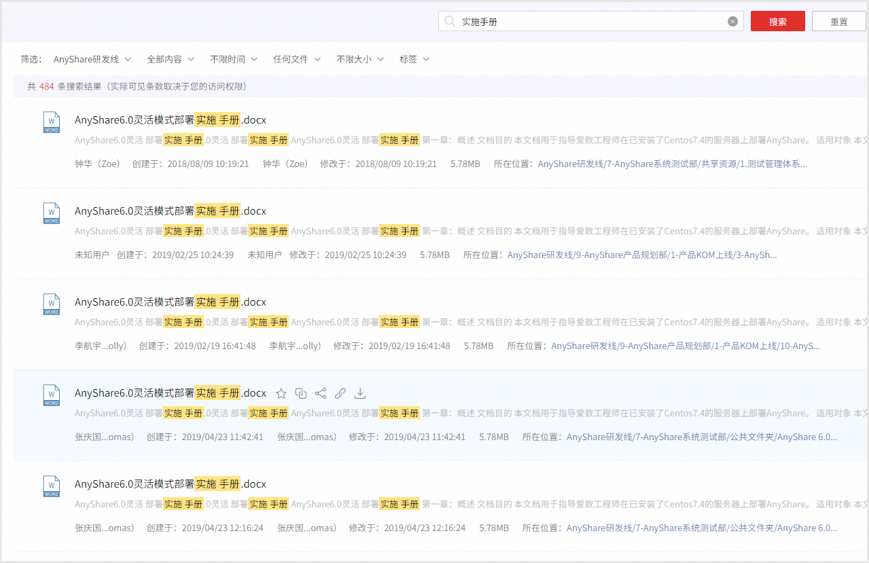
 相似搜索结果模式
相似搜索结果模式
part 1 - 效果展示对比
通过下面的示例我们可以看出,在使用相似搜索结果折叠的情况下,可以更为直观快速的定位到我们需要寻找的文档。
传统搜索模式
相似搜索结果模式part 2 - 相似搜索结果折叠的实现逻辑
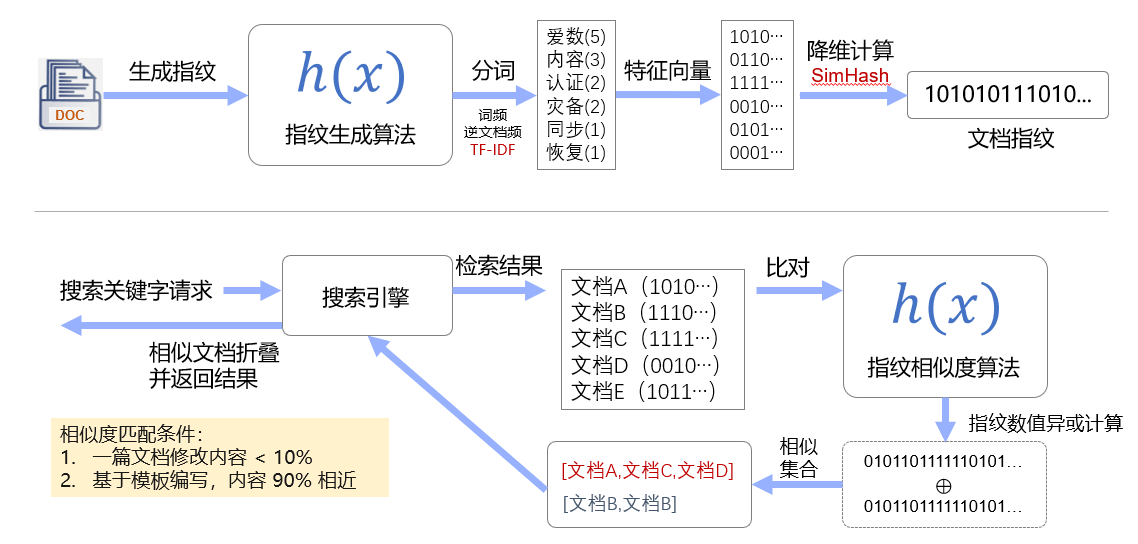
AnyShare Family 7 通过 SimHash 文档指纹生成算法对每个文档生成了文档指纹,当前端发起搜索请求时通过指纹相似度算法进行比对,从而将相似文档放入到一个相似集合中,下面图片很好的演示了这一过程。
part 3 - SimHash 文档指纹生成算法的原理
SimHash(LSH局部敏感哈希的一种),主要思想是降维,将高维的特征向量映射成低维的特征向量,通过两个向量的 Hamming Distance 来确定文章是否重复或高度近似,Hamming Distance 即海明距离,在信息论中,两个等长字符串之间的汉明距离是两个字符串对应位置的不同字符的个数,也就是说,它就是将一个字符串变换成另外一个字符串所需要替换的字符个数。例如:1011101 与 1001001 之间的汉明距离是 2,至于我们常说的字符串编辑距离则是一般形式的汉明距离。

part 4 - 通过搜索结果折叠哪些文档会被识别为相似文档
1、文字内容相同,表达顺序与逻辑差异的文档
AnyShare Family 7 通过 SimHash 文档指纹生成算法对每个文档生成了文档指纹,当前端发起搜索请求时通过指纹相似度算法进行比对,从而将相似文档放入到一个相似集合中,下面图片很好的演示了这一过程。
part 3 - SimHash 文档指纹生成算法的原理
SimHash(LSH局部敏感哈希的一种),主要思想是降维,将高维的特征向量映射成低维的特征向量,通过两个向量的 Hamming Distance 来确定文章是否重复或高度近似,Hamming Distance 即海明距离,在信息论中,两个等长字符串之间的汉明距离是两个字符串对应位置的不同字符的个数,也就是说,它就是将一个字符串变换成另外一个字符串所需要替换的字符个数。例如:1011101 与 1001001 之间的汉明距离是 2,至于我们常说的字符串编辑距离则是一般形式的汉明距离。
part 4 - 通过搜索结果折叠哪些文档会被识别为相似文档
1、文字内容相同,表达顺序与逻辑差异的文档
复制一篇文档,任意调整词组、语句顺序,能够归类为相似文档
2、部分内容修改的文档
复制一篇文档,修改其中字数 < 10% 左右文字,能够归类为相似文档
3、标准模板编写的文档
基于标准模板编写的文档,在文字内容 90% 相近的情况下,能够归类为相似文档
赞
点个赞吧!
请就本文对您的益处进行评级:










