并行重删如何保证效率?(上篇)
传统重删模式大多基于单个节点进行,此方案在大数据时代,容易面临数据访问、处理性能不足,存储空间资源紧张等挑战。AnyBackup 7 采用并行重删技术,通过在多个不同的节点上构建指纹库,并将指纹并行分布于多个节点,有效解决单点性能和存储空间压力问题。
我相信很多人和我有相同的疑问:指纹库分布于多个节点,数据块的指纹会发送到不同的节点进行重删;如果一个数据块的指纹第一次在节点1进行去重并记录,下一次备份时有一个相同的数据块,而它的指纹可能发送至其他的节点,那将会被作为非重复的数据块重新进行去重并写入数据,这样势必会降低重删率和备份性能。
带着这个疑问,我开始做一些探索。
首先,我了解到 AnyBackup 7 的指纹库设计:
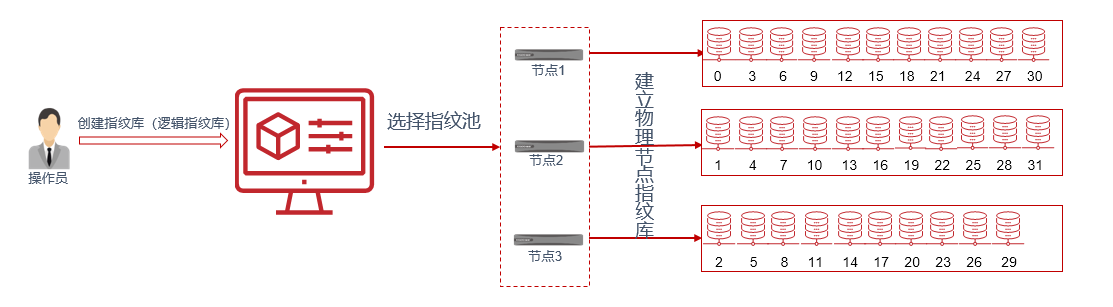
指纹库设计
指纹库分为逻辑指纹库和物理指纹库,以 AnyBackup 7.0.8 为例:
- 逻辑指纹库:逻辑指纹库指操作员界面上建立的指纹库,界面上建立一个逻辑指纹库,后台会建立 32 个物理指纹库,这些物理指纹库尽量平均的分布在指纹池所选的所有节点。
- 物理指纹库:每个节点上真实的指纹库。
为什么是 32 个物理指纹库呢?这是为了适配后续的版本大于 3 个节点的集群环境,这样的设计,可以让重删集群最大可以使用到 32 个节点。
指纹映射
- 数据切片计算出指纹后依照一定映射规则,发送至映射的物理指纹库内进行查询。
- 指纹映射规则一致,保证相同的指纹一定存放在同一个物理节点指纹库内。
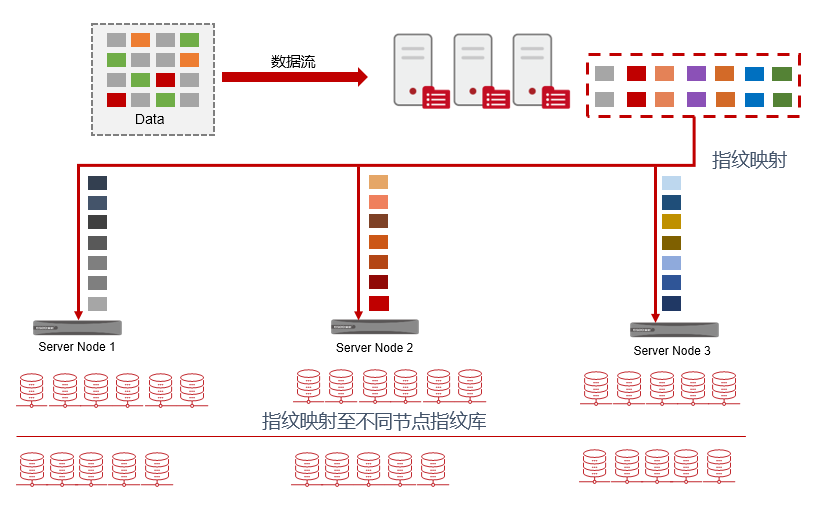 其中的奥秘已经慢慢被揭开:关键就在于指纹映射,通过指纹映射统一的规则,保证相同的指纹一定存放在同一个物理节点指纹库内。从而保证相同的数据块会进行去重,前文提到的疑问中的情况不会发生。可以减少并行重删时每次都要查找全部指纹的时间损耗,并在保证重删率不减少的前提,线性提升单个指纹库的重删容量,可适用于更大数据量的备份场景,备份窗口更小。
其中的奥秘已经慢慢被揭开:关键就在于指纹映射,通过指纹映射统一的规则,保证相同的指纹一定存放在同一个物理节点指纹库内。从而保证相同的数据块会进行去重,前文提到的疑问中的情况不会发生。可以减少并行重删时每次都要查找全部指纹的时间损耗,并在保证重删率不减少的前提,线性提升单个指纹库的重删容量,可适用于更大数据量的备份场景,备份窗口更小。
那么指纹的映射规则具体是如何实现,这里先留一个悬念,在下篇再进行分享。
相关文章:
并行重删如何保证效率?(下篇)



























