
人工智能的范围很广,广义上泛指通过计算机(机器)实现人的头脑思维,使机器像人一样决策。机器学习,则是实现人工智能的一种技术。那么,这种技术到底是什么呢?
机器学习在日常中潜移默化
其实,每天你都会接触到很多次机器学习,只是很多时候意识不到。

当你打开音乐软件或者淘宝时,它都会有“猜你喜欢”的功能,根据你的听歌习惯和浏览记录给你推荐符合你口味的音乐和商品, 像QQ音乐、淘宝这些推荐系统,背后的秘密武器正是机器学习;当你使用google或百度等搜索引擎时,它能给出如此满意的结果,原因之一就是google或百度使用的机器学习算法,学会了如何给网页排序;当你阅读邮件时,你的垃圾邮件过滤器帮助你过滤大量的垃圾邮件,这也是机器学习。
制造智能机器,可以通过编程,让机器做一些基本的事情,比如如何找到从A到B的最短路径——只需要给它一串指令,它就会遵照指令一步步执行下去。有因有果,非常明确。
但是大多数情况下,我们不知道如何编写AI程序来做更有趣的事情,如网页搜索、智能推荐、反垃圾邮件等。那我们能不能找到其他的方法来做这些事情呢?答案自然是肯定的,机器学习就能做到!
机器学习根本不接受你输入的指令,相反,它接受你输入的数据! 我们不需要一步一步地编写指令,而只需要将数据输入,机器学习算法就能自己学习出一套模型,并且随着数据输入越来越多,模型就会变得越来越准确。也就是说,机器学习是一种让计算机利用数据而不是指令来进行各种工作的方法。
从智能识瓜到智能预测
我们用一个简单通俗的例子来说明什么是机器学习。假设我们我们去买西瓜,我们想要挑选出最好的西瓜,可是如何挑选呢?想一想我们做决策的过程,妈妈告诉我说瓜藤呈捲曲状西瓜比瓜蒂是直的好 ,所以我们有了一个简单的判别标准:瓜藤是捲曲状的西瓜是好西瓜。
如果用计算机程序来帮我们挑西瓜,会写出如下的规则:
![]()

后来我们发现,捲曲状瓜藤的西瓜可能并不甜,甜的一般瓜蒂下方有些微凹陷,于是判别标准需要再多加一条:好的西瓜瓜藤是捲曲状的而且瓜蒂下方有些微凹陷。计算机程序则需要把规则修改成如下:
![]()

但是我们慢慢又发现,表现光滑花纹清晰的西瓜更甜,又学到拍西瓜时,发出“咚、咚”的清脆声是更甜......我们挑选西瓜的次数越多,积累的经验越多,挑选到好西瓜的概览就越来越大。大家或许已经意识到,西瓜的好坏受很多错综复杂的因素影响,手动地定制规则变得很困难。而且,判别标准变得越来越复杂且难以描述,我们也没有办法好好地写出一个清晰的程序,来判别什么是好西瓜,什么是坏西瓜。

如果用机器学习呢?让计算机自己去学习如何挑选好的西瓜会怎么样呢?
这个时候,我们不需要告诉计算机如何一步一步地去判断什么是好的西瓜,我们只需要从市场上的西瓜里随机的抽取一定的样品(机器学习中叫训练数据),记录每一个西瓜的特征,比如颜色、大小、产地等(机器学习中叫特征),再记录下这个西瓜好不好(机器学习中叫标记)。然后我们将这些数据提供给一个机器学习算法,它就能学习出一个关于西瓜的特征和它是不是好西瓜之间的一个模型。
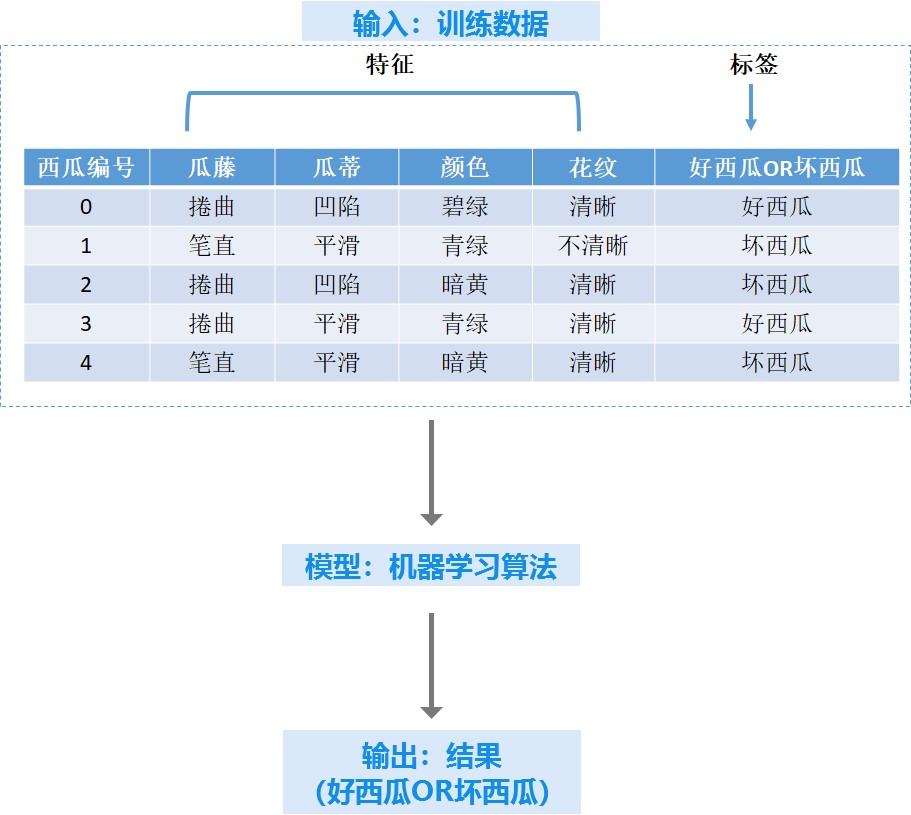
下次我们再去买西瓜,我们将新的西瓜的特征(机器学习中叫测试数据)输入计算机,训练出的模型就会直接输出这个西瓜是不是好瓜。我们不需要考虑挑选出好西瓜的细节,只需要告诉模型西瓜的特征就直接知道西瓜是不是好西瓜了。更重要的是,我们可以让这个模型随着时间变得越来越好,当这个模型读进更多的训练数据,它就会更加准确,并且在做了错误的预测之后进行自我修正(机器学习中叫增强学习)。
上面这个过程其实就是一个机器学习的过程,我们注意到,我们有一部分带标签的训练数据(知道是不是好西瓜的数据),这时候我们称之为监督学习。如果我们面对很多西瓜,只知道这些西瓜的特征,完全无法判断这些西瓜是不是好瓜怎么办呢?也没有关系,我们可以将观察到的西瓜特征输入计算机,机器学习方法自己获取数据的内部模式,通过分析输出,往往可以得到有价值的信息。这种方式,我们称之为非监督学习。这时候我们没有带标签的数据训练数据(只知道西瓜的特征,而不知道是否是好西瓜)。
这还不是最棒的地方,最棒的地方在于,我们可以用同样的机器学习算法去训练不同的模型,比如我们可以使用同样的机器算法来预测苹果, 橘子的模型。这是常规计算机程序办不到的。
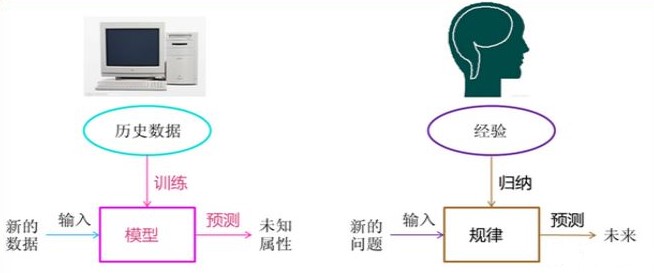
通过这个小故事,我们回过头来看一看我们做出决策方式与机器学习做决策的方式:我们在成长、生活过程中积累了很多的历史与经验,定期地对这些经验进行“归纳”,获得了生活的“规律”。当遇到未知的问题或者需要对未来进行“推测”的时候,我们使用这些“规律”,对未知问题与未来进行“推测”,从而指导自己的生活和工作。
机器学习中的“训练”与“预测”过程可以对应到我们的“归纳”和“推测”过程。通过这样的对应,我们可以发现,机器学习的思想并不复杂,仅仅是对人类在生活中学习成长的一个模拟。由于机器学习不是基于编程形成的结果,因此它的处理过程不是因果的逻辑,而是通过归纳思想得出的相关性结论。
不知道大家是不是对机器学习有一个简单的认识了呢?
机器学习的应用场景
机器学习有很多的应用场景,例如:
♦ 营销类场景:商品推荐、用户群体画像、广告精准投放
♦ 金融类场景:贷款发放预测、金融风险控制、股票走势预测、黄金价格预测
♦ SNS关系挖掘:微博粉丝领袖分析、社交关系链分析
♦ 文本类场景:新闻分类、关键词提取、文章摘要、文本内容分析
♦ 非结构化数据处理场景:图片分类、图片文本内容提取OCR
♦ 其它各类异常检测场景:用户行为异常检测、信用诈骗检测、入侵检测、网络安全异常检测等
当遇到涉及大量数据和许多变量的复杂任务或问题,但没有现成的处理公式或方程式时,可以考虑使用机器学习。例如,如果需要处理以下情况,使用机器学习是一个很好的选择:
.png)
传统运维 VS 常规监控 VS 异常检测
爱数AnyRobot推出的第一个机器学习场景是异常检测,主要用来识别异常。
例如,在线采集而来的有关用户的数据,一个特征向量中可能会包含如:用户多久登录一次,登录使用的设备,登录的地点等。我们可以根据这些特征构建一个模型来判别用户账号使用安全,是否存在被盗用现象。再例如,检测一个数据中心,特征可能包含:内存使用情况,被访问的磁盘数量,CPU的负载,网络的通信量等。根据这些特征可以构建一个模型,用来判断某些计算机是不是有可能出错了。对应到买西瓜的例子,我们在计算机中输入西瓜的特征,它快速识别出里面与其他西瓜不同西瓜的过程即是异常检测!输入的数据越多,识别的准确率就越高。
那么AnyRobot是如何实现异常检测呢?下面让我们举例看一看AnyRobot异常检测如何解决一个真实的场景。
▼
某公司有支撑业务运转的服务器100+,运维工作中除了要维持平台的稳定运行以外,还得对服务器的性能进行优化。让服务器发挥出良好的工作性能是稳定运行的基础。
传统的运维是如何做的呢?
在还没有监控系统的时候,运维人员只能在服务出现问题的时候被动响应。首先,他需要去查每一台服务器的性能数据的每一个指标,并对比其历史数据才能筛选出疑似故障的服务器。排障操作繁琐、工作量大、处理时间长,而且准确性与运维人员的专业能力强相关。也许在运维人员真的找到问题所在时,已经对公司造成了不可估量的损失。
那么,有了监控系统之后呢?
面对100+服务器,每一台服务器又因为处理业务的差异性具有特异性。运维人员花了大量的时间和精力写了数百条告警规则,每天都会收到成千上万条告警信息。面对如此多条告警规则,运维人员如果一条规则编写不恰当或者没有考虑全面都会导致真正的告警被淹没。更重要的是,影响性能指标的维度很多而且不是完全相互独立的,我们不能单单就CPU的使用率超过80%就判定某一台服务器出现故障。同时,很多问题场景是很难用告警规则去描述的。就像我们在挑选好的西瓜的时候,有些条件我们难以用语言描述出来,我们也不能单单就瓜藤呈捲曲状就判定这是一个好西瓜。以这种人工添加告警规则的方式来监控服务器的健康状态,仍然是被动式的响应问题状态,有的问题场景告警无法覆盖,有的问题出现导致真正的告警被淹没,无法实现SLA。
那么如果我们用爱数AnyRobot异常检测呢?
AnyRobot异常检测提供主动的异常管理。基于每台服务器自身的历史经验建立模型分析当前健康状态,判断服务器近期是否会发生故障,并为服务器的资源规划提供有力的依据。即使数据量多,数据特征复杂且不是完全独立的,抑或数据具有特异性!你都可以完全放心地交给 AnyRobot。
AnyRobot异常检测四步法
我们来看看AnyRobot具体是怎么做的。
1.数据接入
将服务器的性能日志信息传入AnyRobot进行解析过滤。
2.选择检测算法与计算维度
选择多维度异常检测,选取CPU的平均值、内存的最大值、网络流量的平均值、磁盘容量的最大值、业务访问量的平均值 这5个维度进行计算。由于每一台服务器处理业务的差异性,资源情况具有特异性,所以我们通过服务器名称对日志进行拆分,以每一台服务器自身作为基线,基于服务器的历史经验建立模型。此时,我们也可以查看每一个维度的数据特征以及整体趋势。
3.选择合适的模型参数
我们可以根据实际情况对模型进行调整,以提高模型的准确率。
4.应用模型
设置定期执行模型计算任务,我们设置了每天的下午6点定期执行最近7天的数据,用户可以根据实际情况设置定期执行的周期。
只需要4步!不管你的数据量有多少,数据特征有多复杂,特征之间有多少关联,有多少台差异化的服务器。AnyRobot的性能监控建模都只需要4步!如果你还想增加分析维度,只需要添加计算维度即可,多少维度AnyRobot都不在话下。摆脱费脑地去罗列可能出现异常的情况,手动创建繁琐的告警规则的巨型困扰。
▼
AnyRobot模型计算结果有哪些优势?
对于模型计算的结果,首先,我们能清晰明了地看到每一台服务器的健康状态。
没有出现异常点:表示服务器处于健康状态,对资源的使用一切正常,在未来一段时间内(7天内)可能正常。
偶尔出现异常点:表示服务器处于亚健康状况,对资源的使用存在一定的风险,如高峰期网络流量太高,但仍然未达到影响机器正常运行的程度,运维人员需要考虑机器I/O类型或者扩容,以便应对短期内可能产生的压力。
出现的异常点多:表示服务器处于病态,对服务器的某种资源的消耗以及达到上限,如磁盘已满,需要运维人员立即处理。
面对100+台服务器,运维工作中我们很难去关注每一台服务器的性能状态。AnyRobot能够在众多服务器中找到并定位健康状态不佳的设备,你只需要重点关注它们即可,大大减少了工作量。同时,你无须因为服务器的特异性而苦恼,因为AnyRobot的算法以每一台服务器本身为基线的。
.png)
每台服务器异常概览
其次,对于健康状态有问题的服务器,我们能快速找到异常原因。AnyRobot通过因子分析方法,对异常现象深度探析,聚焦具体的异常原因。对于异常点,我们能看到具体的异常信息,同时也能看到异常原因。
例如,异常点出现最多的服务器:异常时我们看到此时的cpu占用和内存利用率都很高,但是业务访问量却很少,说明我们的环境出现了问题,需要及时处理。
.png)
某台服务器异常的详细信息(省略部分维度)
又例如,出现了三个就近连续的异常点的服务器:异常时我们能看到业务访问量很高时,其他资源的使用也相应增高。我们可以判断出此时已经达到了业务处理的临界点,如果后续要处理访问量更多的业务,需要增加此服务器的配置和资源。
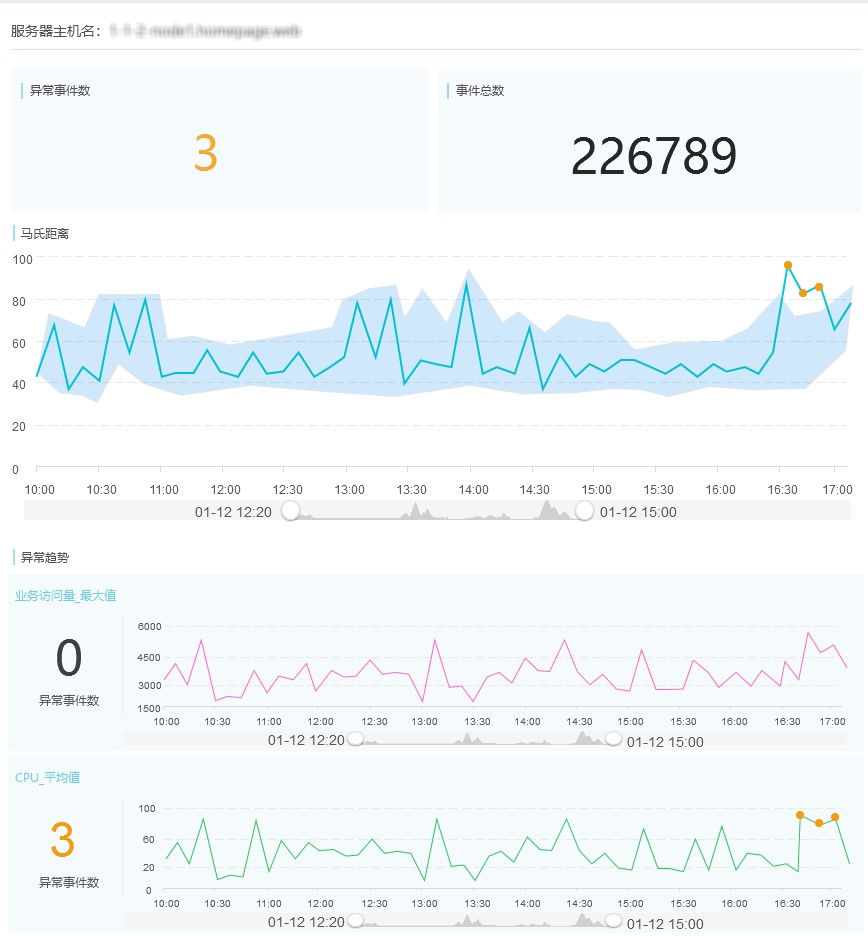
某台服务器异常的详细信息(省略部分维度)
计算维度统一清晰的可视化呈现,让我们随时能掌握服务器的异常情况。同时,AnyRobot对异常现象的深度剖析,我们定位异常原因的速度蹭蹭蹭往上涨涨涨。
AnyRobot异常检测对服务器状态进行监控,在众多的服务器中快速定位异常设备与异常原因,随时发现服务器的资源消耗情况。帮助运维人员输出重要的日常服务运行报表,以评估服务/业务整体运行情况,发现服务隐患,同时为服务器做资源规划提供强有力的依据。
看到这里,大家是不是很想马上去用一用AnyRobot的异常检测功能呢?之后,我们将推出越来越多的应用场景,智能运维不是梦,请大家拭目以待!
想要了解AnyRobot更多信息,请点我查看










